

用户流失预警分析

本文所涉及到的分析框架和方法论等具有较强的通用性,可供有需要的同学了解参考。
一、分析背景
“根据美国贝恩公司的调查,在商业社会中5%的客户留存率增长意味着公司利润30%的增长,而把产品卖给老客户的概率是卖给新客户的3倍。所以在‘增长黑客’圈内有一句名言:留住已有的用户胜过拓展新的客户,也就是俗称的‘一鸟在手,胜过双鸟在林’。”
——引用自《增长黑客》
用户留存和用户流失是一组相对的概念。诸如获得一个新客户的成本是保持一个老客户的5倍等经过众多商业实践总结出来的数据都证明了一个事实——提升用户留存率,减少用户流失,对于任何一家企业来说都是非常重要。
而随着互联网特别是移动互联网的高速发展,传统模式下的很多发展瓶颈得到了重大突破,成本结构也发生了显著变化。但对于企业来说,用户留存依然是反映企业及产品核心竞争力的关键要素。
在用户生命周期管理(CLM)的分析框架下,不同的用户生命周期阶段我们需要考虑不同的问题,制定不同的用户管理策略,不断改善用户体验的同时,实现用户生命周期价值(CLV)的最大化。
不同用户所处的阶段可能是不一样的,且每一个阶段的时间跨度和展现形式可能也有所不同。针对用户衰退阶段,构建高危流失用户的预警机制,制定面向高危用户挽留策略,是延长用户生命周期、提升用户留存的重要举措,这也是本文将要重点阐述的研究内容。
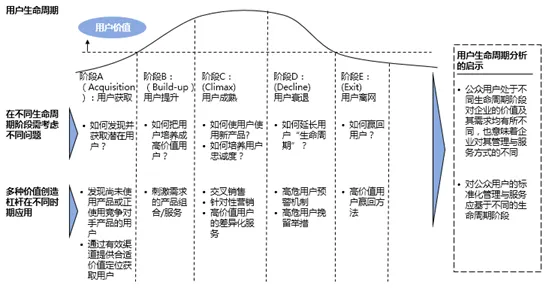
图1:用户生命周期
关于对用户数据如何开展分析挖掘,目前业界已有不少成熟的方法论,而我们的分析流程也是在这些方法论的指导下有序开展的。当前业界主要的两大方法论分别是SEMMA方法论和CRISP-DM方法论。其中SAS公司提出的SEMMA方法论,即抽样(Sample)、探索(Explore)、修改(Modify)、建模(Model)、评估(Assess),强调的是这5个核心环节的有机循环。
而SPSS公司提出的CRISP-DM是英文缩写,全称为跨行业数据挖掘标准流程(Cross-Industry Standard Process for Data Mining),突出业务理解、数据理解、数据准备、建模、评价和发布这几个环节,强调将数据挖掘目标和商务目标进行充分结合。
在具体实践中,CRISP-DM强调上层的商务目标的实现,SEMMA则更侧重在具体数据挖掘技术的实现上。只有将两种方法紧密联系在一起,才能达到更好地达成数据分析挖掘的效果。
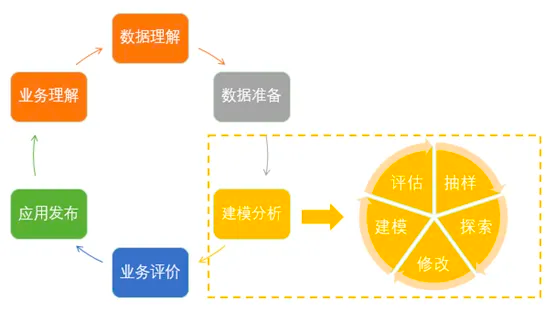
图2:数据分析挖掘方法论
二、流失预警模型构建
基于上述方法论,下面结合具体的业务场景,详细介绍用户流失预警的分析思路及模型建设过程。
2.1 业务理解
针对某业务用户活跃度下降、沉默用户比例较高的业务现状,着手建立高潜流失用户预警及挽留机制,以期提升用户留存,拉动活跃,“防患于未然”。而落脚点则是建立一套流失预警的分类模型,预测用户的流失概率。
基于上述需求,首先我们要明确“用户流失”的定义,使得分析的目标更符合业务理解及分析要求。
2.1.1 用户流失行为定义
这里罗列了流失分析可能需要考虑的三个维度:动因、程度和去向。不同业务场景下流失分析可能需要综合考虑多个维度,以制定最为合理的分析目标。
1)流失动因
- 客户主动流失(VOLUNTARY CHURN)——客户主动销户或者改变当前的服务模式;
- 客户被动流失(INVOLUNTARY CHURN)——客户因为违规或欺诈等行为被停止服务及强行关闭账户等行为。
2)流失程度
- 完全流失——客户发生关闭所有与企业服务相关账户和交易等不可恢复或者很难恢复的行为;
- 部分流失(PARTIAL CHURN)——客户并未关闭账户但是交易水平突减到一定水平之下,例如在产品使用场景下用户使用频率突降了50%等等。
3)流失去向
- 外部——客户关闭或减少了在当前机构的业务而转向了其它竞争对手;
- 内部——客户关闭或减少了在当前机构的部分业务而转向了当前机构的其它业务。
可见,对于流失的理解可以是多方位的,需要结合具体的场景和需求。这里我们只简化考虑用户在某项业务主动部分流失的情况。
2.1.2 Roll-rate分析
针对流失的目标定义,我们锁定一批用户,观察其在后续业务使用方面的持续沉默天数,滚动考察用户回流比例。我们发现,当QQ某业务用户沉默天数超过两周后,回流率环比已经低于10%且后续趋势平稳,因此我们将本次该业务流失分析的目标定义为:用户该业务使用出现连续沉默14天及以上。基于该定义着手构建建模分析样本。
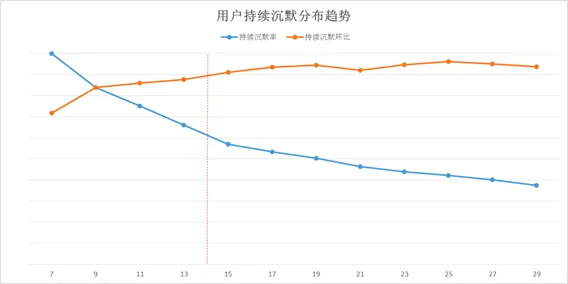
图3:Roll-rate分析
2.2 数据理解
针对用户流失预警这一分析目标,我们重点考察用户活跃类指标,构建流失预警分析建模指标体系:
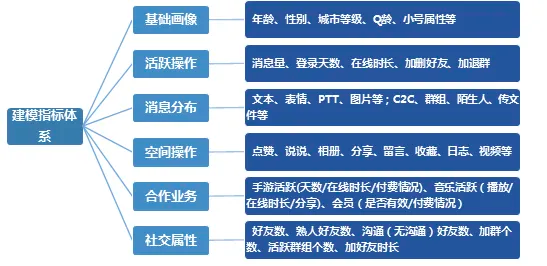
图4:建模指标体系
2.3 数据准备
2.3.1 样本构造
流失预警分析样本数据选取:
1)锁定某日业务使用活跃用户,统计其在后续14天的活跃情况;
2)由连续14天沉默账号和14天有活跃账号构成样本,并打上相应标签;
3)统计样本账号在观察点前8周的行为特征,按周汇总输出,同时加入包括基础画像的特征属性。
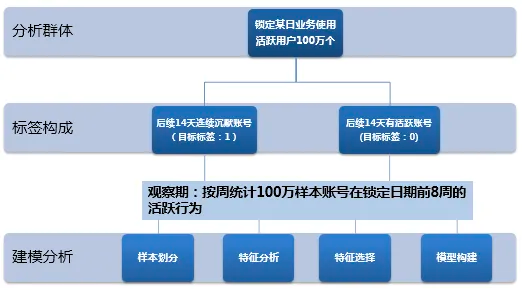
图5:建模样本构造
2.3.2 数据质量检验
这项工作的重要性不言而喻,正所谓“垃圾进,垃圾出”,基础数据如果无法保证良好的数据质量,分析研究工作便会举步维艰甚至是徒劳,分析得出的结论也是无效或者是错误的。因此,我们需要建立一套完整有效的数据质量检验流程,这里暂且不就这部分内容展开介绍了。
2.4 建模分析
根据SEMMA的数据挖掘方法论,建模分析过程主要包括抽样(Sample)、探索(Explore)、修改(Modify)、建模(Model)和评估(Assess)这五个关键环节。而下面就这五个环节的技术实现过程中涉及到的一些关键点进行简要阐述:
2.4.1 粒度的选择
根据分析目标,选择合适的分析粒度。不同的粒度意味着需要对数据需要做不同方式的处理以及应用。比如说我们是基于账号还是自然人,这个问题需要在模型建设初期就明确下来。目前流失预警分析以QQ用户账号为分析单元。
2.4.2 抽样与过抽样
抽样就是从原始数据中,抽取一定量的记录构成新的数据。对于原始数据规模非常大的场景来说,抽样往往是必要的,可以大大提升模型训练的速度。当然,随着分布式计算等大规模数据处理及分析能力的引入,使用完整的、大量的数据样本进行模型训练的可能性也越来越高。
而过抽样则可以理解为多抽取稀有的标签,而少取常见的标签,这种抽样方法在建模过程中相当常见。比如本次流失分析的场景下,流失用户作为目标样本,相比整体大盘来说肯定是属于稀有的标签。为保证模型的有效性,我们需要按照一定配比,建立由流失和非流失用户构成的建模样本,并分别打上‘1’和‘0’的状态标签。两类样本的比例关系并没有固定标准。一般情况下,目标标签样本占建模数据集的比例在20%-30%,会产生较好的模型效果。
另外,也可以通过样本加权的方式进行过抽样,实现增加建模数据集密度的同时而不减少其规模。具体操作上一般将最大的权重设为1,而其他所有权重都取小于1的值,以此减少模型过拟合的风险。
2.4.3 数据探索与修改
数据探索即对数据开展初步分析,包括考察预测变量的统计特性及分布、缺失及异常值发现及处理、变量关联性及相关性分析等单变量或多变量交叉分析。
1)变量离散化
在对建模数据进行单变量分析及预处理的过程,对变量进行分组,目的在于观察变量与目标事件的对应趋势,判断是否与实际业务理解相符,从而决定变量是否适用。同时通过变量分组,减少变量属性个数,有助于避免异常值对模型的影响,提升模型的预测和泛化能力。
具体做法是对变量按照一定规则进行划分,比如对于连续型的数值变量,按照分位点对变量取值进行等高划分为大约10个区间,具体如下:
图6:单变量分布
2)WOE(Weights of Evidence)值计算
在变量分组的基础上,我们这里使用证据权重WOE对变量取值的编码转换,作为最后模型的输入。WOE的计算公式如下:
WOEattribute= log(p_non-eventattribute/p_eventattribute)
其中:
p_non-eventattribute= #non-eventattribute/#non-event(模型变量各特征分段下非事件响应用户数占总体非事件响应用户数的比例)
p_eventattribute= #eventattribute/#event(模型变量各特征分段下事件响应用户数占总体事件响应用户数的比例)
从这个公式中可以看到,WOE表示的实际上是“当前分组中非响应用户占所有非响应用户的比例”和“当前分组中响应的用户占所有响应的用户的比例”的差异。WOE越大,这种差异越大,这个分组里的样本响应的可能性就越小,即用户流失风险越小。
将字符型和数据型变量分组后的WOE值,可以作为回归模型训练的输入。
3)变量选择
关于模型待选变量的选择标准主要从四个方面加以考虑:变量的预测能力、变量的稳定性、变量与业务的趋势一致性、变量间的相关性、变量的预测能力。
变量的预测能力:
在变量预测力方面,选择计算信息值IV(Information Value)来量度。IV值一方面可以用于选择预测变量,另一方面也可以作为分组是否合适的判断依据。
IV的定义和熵(平均信息量)的定义很相似:
IV =∑((p_non-eventattribute- p_eventattribute) * woeattribute)
一般情况下,IV的衡量标准如下:

表1:IV衡量标准
变量的稳定性:
变量的稳定性主要是跨时点考察特征分段样本分布是否存在明显异动。对波动性较强的变量则需要考虑是否需要结合时间序列做衍生处理,又或者被剔除。稳定性指标通过PSI(Population Stability Index)来度量。具体计算公式如下:
Index=∑((比较时点分段样本百分比-基准时点分段样本百分比)*ln(比较时点分段样本百分比/基准时点分段样本百分比)
一般情况下,PSI的衡量标准如下:

表2:PSI衡量标准
变量与业务的趋势一致性:
这个标准可以结合业务知识、特征分布及WOE进行综合判断。
变量间相关性:
计算变量间的相关系数,当评分模型变量间的相关性过高,会产生共线性(collinearity)的问题,导致使模型的预测能力下降,甚至出现与预测结果相反无法解释的现象。为避免变量间的高度相关削弱模型预测能力,对相关系数较高的变量集合可通过IV择优选取。
2.4.4 建模
前面我们通过大量的特征分析工作圈定了有效模型入选变量,接下来通过模型算法的选择调用最终输出模型结果,给每个用户单元计算流失概率。作为一个分类问题,目前我们有比较多的模型算法可以尝试,比如说逻辑回归和决策树。通过模型比较,我们最终选择逻辑回归进行建模。由于逻辑回归是业务已经比较成熟的分类算法,大多数分析同学应该都比较了解,这里就不再赘述其原理。
2.5 模型评价
对于一个模型是否达标,我们一般会从以下几个方面去考量:
1)是否达到符合应用要求的准确性水平
这里我们可以通过Lift Charts(又叫 gains chart)、ROC Charts、KS等评价指标来对模型性能进行评估比较。
2)是否具有较高的稳定性
同样的,我们可以借鉴变量分析里面的稳定性系数PSI来衡量及监控模型的稳定性。
3)是否简单
这个标准主要是从模型部署的角度考虑,模型如果足够简单,将更有利于模型的IT部署应用。
4)是否有意义
即在模型变量及其预测结果方面具有较强的可解释性。这对于某些场景来说要非常看重的指标,比如说在银行信贷的信用评分模型的应用上。它是技术与业务有效连接的重要桥梁,有利于业务方更好理解模型并有效指导业务开展。当然,随着机器学习领域一些高级算法的研究使用,可解释性要求在某些场景下已经不属于必要条件。
2.6 模型应用
关于模型应用,我们主要聚焦在以下两个方面:
1)用预测模型得到影响流失的重要因素
通过单变量分析找出对业务有突出影响的一系列“Magic Number”。为什么叫“Magic Number”?顾名思义,这个数字能给业务增长带来魔力般的神奇促进效果。通过对关键影响指标的量化分析,可以帮助业务有效制定运营目标。
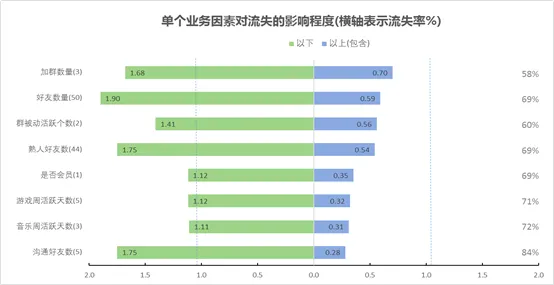
图7:Magic Number
如上图所示,在流失预警的分析中,我们发现若干对用户流失显著相关的特征指标,比如好友数。好友数量达到50个及以上的用户流失率只有好友数50个以下用户的30%左右,可见好友数指标对于用户留存存在正向作用,再次验证我们大力开展好友推荐、优化QQ用户好友关系结构的必要性。
2)用预测模型预测客户流失的可能性
利用模型输出的概率结果,对流失概率最高的一部分用户,可以开展针对性的运营管理,比如设计有效的唤醒机制、好友推荐、个性化推荐以及合作产品引导等,挖掘用户的应用需求点和兴趣点。同时建立分析-应用-反馈的闭环流程,持续对用户留存流失进行监控管理,及时发现问题,以指导模型优化及策略更新。
三、优化研究方向
可以尝试从以下两个方面开展优化分析:
3.1 用户群体细分
针对不同类型的用户分别搭建流失预警模型。
3.2 用户行为分析
分析用户产品使用行为及内容偏好,挖掘用户使用习惯及兴趣点,实现个性化推荐,拉动用户活跃。
四、结语
在用户流失预警这个分析案例中,我们结合业务现状,在用户生命周期管理的大框架下,采用业界较为成熟的数据分析挖掘方法论,开展数据分析工作。这里面重点介绍了特征分析的方法,这是我们在做用户数据分析过程非常重要且必不可少的部分。
而在特征分析过程中,我们可以更加深入地了解业务特性,输出更多的数据价值。这也是本文所希望传达重要信息。由于知识和篇幅所限,有很多细节没能阐述得特别深入,有些方法也许不是最优的做法,欢迎对BI有兴趣的同学加强交流,共同进步,更好地将数据价值应用到实际业务中。
作者:alvinpan,腾讯CSIG数据科学家
来源公众号:腾讯大讲堂(ID:TX_DJT )
扫一扫 微信咨询

商务合作 联系我们
 微信扫一扫
微信扫一扫 
