
六个月前,由OpenAI研发的文生视频大模型Sora横空出世,给了科技圈一点大大的震撼。
用AI生成视频并不是新鲜事,只不过此前一直无法突破合成10秒自然连贯视频的瓶颈。而Sora在发布时就已经能合成1分钟超长视频,视频质量画面也效果惊人。
尽管Sora一直没有开放公测供用户体验,但其底层架构还是被扒了个遍。被称之为“Sora路线”的DiT,全称为Diffusion Transformer,本质是把训练大模型方法机制融入到了扩散模型之中。
自此,相关平台不甘落后,纷纷摸着Sora过河,你方唱罢我登场,竞争不可谓不激烈。有媒体统计,国内有至少超20家公司推出了自研AI视频产品/模型。入局玩家纷杂。
在刚刚过去的7月,商汤推出最新AI视频模型 Vimi,阿里达摩院也发布AI视频创作平台“寻光”,爱诗科技则发布PixVerse V2,快手可灵宣布基础模型再次升级,并全面开放内测,智谱AI也宣布AI生成视频模型清影(Ying)正式上线智谱清言。
互联网企业之间的赛场也有了新故事。字节跳动是第一批发布AI视频模型的选手,3月率先发布剪映Dreamina(即梦),三个月后,快手可灵AI正式开放内测。
AI视频大模型赛道如此之“卷”,究其原因,无疑是其背后蕴藏的商业空间与想象力。不过,用户更关心的是产品本身。这也是行业必须要直面的问题:AI视频大模型到了哪一步?Sora带来的“光环”,究竟值不值得期待?
目前深度学习的框架,“数据是燃料、模型是引擎、算力是加速器”。在掌握模型搭建方法后,不断投喂数据并提升算力和准确性是各平台采取的主要策略。而进展是有限的。普遍来看,大模型在生成具有连贯性和逻辑一致性的视频方面仍然存在困难。
本次我们选取几个国内头部视频生成模型进行实测,包括可灵、即梦、PixVerse、清影(智谱清言),具体直观地测试不同的模型表现。
为尽可能客观地比较测试结果,我们采用如下设定:
- 使用统一的中文提示词,包括简易提示词和复合提示词;
- 测试包含图生视频和文生视频两种方式;
- 测试场景包括大模型对人物、动物、城市建筑等的生成效果;
- 模拟新手用户使用场景,统一采用各模型平台电脑端默认设置;
- 展示呈现采用一次生成结果,不进行二次调整优化。
以下是各模型的实际生成效果:
场景1:二次创作场景
提示词:做出加油的动作后做出鬼脸,吐舌头并眨右眼。
场景说明:使用梗图《握拳宝宝》,模拟用户二次创作,测试模型对于图片的理解和生成能力。对于模型主要的难点在于需要理解“鬼脸”的含义,并能对“吐舌头”和“眨眼”两个动作做出反馈和生成。现阶段,模型一般只能识别一个动词。

网络上曾经爆火的“握拳宝宝”

↑即梦:主体的手部、嘴部产生了明显畸变,对于提示词动作的理解没有非常明显。

↑可灵:主体动作流畅自然,具有真实感,对于提示词动作理解不够到位。

↑PixVerse:主体动作流畅自然,能够做出提示词相关的动作,这是几个生成视频中唯一一个做出“眨眼”动作的模型。

↑清影:不敢说话了,我怕说错了一不小心被吃掉。
场景2:人物吃东西场景
提示词:一个亚洲年轻男性在家里用筷子津津有味地吃一碗面条,风格真实,类似于电影《天使爱美丽》,环境舒适温馨,镜头逐渐拉近对准人物。
场景说明:对于模型来说,需要围绕“亚洲年轻男性”“筷子”“面条”生成视频,同时要理解电影风格和环境,并按照指示进行运镜。更重要的是,通过吃饭这个场景可以更清晰地让模型展示手部细节,并通过吃面条这个动作来展示模型对于物理世界的理解。

↑即梦:第一帧很帅,光影也很自然。但依旧存在脸部和手部畸变的问题,以及模型明显不能够理解筷子的使用方式和面条的食用方式。

↑可灵:非常惊艳的视频!环境的光线、人物的坐姿和使用筷子的手部姿势都非常真实,甚至嘴部的油光反射都清晰可见,不愧是据说可灵最擅长的吃播领域。唯一是面条的运动轨迹有一些小暇疵。

↑PixVerse:惨不忍睹,甚至还被动卡出了一个不连贯的分镜,也没有理解运镜。

↑清影:如果不看主体人物动作,其实还算过得去。光线、环境和氛围都到位了。
场景3:动物拟人场景
提示词(简单版):一头大熊猫戴着金边眼镜在教室黑板前讲课。
提示词(复杂版):电影胶片感风格的场景中,一头大熊猫戴着金边眼镜,在教室黑板前讲课。它的动作自然流畅,周围是充满质感的教室环境,学生们认真听讲。整个场景如同电影画面,光影处理细腻,色彩饱满。电影胶片感风格,气氛温馨,8K电影级。
场景说明:该场景通过设置两版提示词,来测试大模型对于想象力的理解。简单版提示词仅有大熊猫、金边眼镜、黑板,模型可以通过这三个关键词生成具有可自主添加其他内容的视频,来展现模型的想象力和细节搭建;复杂版提示词按照清影内设的提示词调试小程序生成,涉及场景、风格、人物、环境、色彩、氛围和清晰度等,测试模型的细节刻画。
先看简单版提示词生成的效果:

↑即梦:很不错的视频生成,除了“金边眼镜”外,要素齐全,神态动作也非常自然,光影非常优秀。黑板上的字甚至有些以假乱真。

↑可灵:各种素材都齐了,但是没能特别理解讲课和吃竹子的区别。为了减少失误,画面整体相对单调,没有添加更多细节。

↑PixVerse:要素都齐全,风格也不错,就是眼镜稍微有点出戏(也比没有强)

↑清影:完全没有领悟提示词的意思表达
升级提示词后的效果:

↑即梦:效果依然不错,光影理解也在线,唯一小瑕疵还是眼镜部分,有畸变,以及好像不太能理解“讲课”这一场景的座位排列。

↑可灵:真·熊猫大师讲课图,没得说,优秀!

↑PixVerse:模型自己添加了运镜和细节成分,最后有一些扭曲,整体效果跟前一版差不多。

↑清影:有景深和运镜,画面质感还需要提升,相比前一版有了很大进步。
场景4:科技想象场景
提示词(简单版):充满科技感的未来城市一角,仰视视角。
提示词(复杂版):在充满科技感的科幻风格未来城市中,使用推近镜头,展现建筑和交通工具的细节,无人机在空中穿梭,天气晴朗,阳光洒在高楼大厦的玻璃幕墙上阳光透过高楼的缝隙洒下,周围环境充满未来感,科幻风格,气氛激昂明朗,HDR高动态。
场景说明:该场景同样设置两版关键词,简单版只给出科技感、城市和视角三个关键词,由模型填充生成剩下的内容;复杂版提示词同样使用清影的提示词调试程序生成,涉及风格、运镜、场景、环境、色彩、气氛和清晰度。一方面,该场景主要测试模型在不同颗粒度的提示词下所生成的视频内容丰富性;另一方面。“未来”是现实物理世界与想象世界的结合,可以测试模型对于建筑、光影和科幻的理解。
同样先看简单版:

↑即梦:运镜角度、色彩等方面做得都很好,突出了科技感,对于提示词的理解是到位的。

↑可灵:不出错的方案。建筑有畸变,对于“未来”的想象力有一些欠缺,仅仅是城市建筑的堆砌。不过能够在建筑外立面添加LED大屏,也算是一个亮点。

↑PixVerse:科幻感十足,交通工具、城市、环境都做得非常到位。不过好像没有特别理解仰视视角。

↑清影:倒是对仰视视角非常有心得体会,但是色彩和“未来城市”对理解依然还是差一些。
再看复杂提示词版生成效果:

↑即梦:很优秀的视频了,除去无人机的物理运动方式不能完全理解以外,对于提示词和风格的理解和把握非常到位。

↑可灵:依然是不会出错的方案,有一些畸变,就是看起来好像是北京动物园公交枢纽的实拍是怎么回事。

↑PixVerse:有点抽象的科幻,不太知道该怎么评价。畸变有些严重,但科幻感还是很足的。

↑清影:阳光很好,以至于只能看见玻璃幕墙。
除了场景应用,我们还从另外四个维度对所选取的四个大模型进行了测评:
视频生成质量和清晰度
内容生成准确性、一致性和丰富性
使用成本和价格
生成速度和交互界面
基于「科技新知」的测试情况,在视频质量和清晰度方面,可灵大模型在四个模型中更胜一筹,例如在生成大熊猫视频时,其能够较为清晰细腻地表现出大熊猫毛发的纹理、质感和色泽;对于物体的边框勾勒也区分明确,画面更真实,相对来说物体畸变也是最少的。清晰度方面,几个大模型生成效果都还不错,PixVerse效果相对落后。
从准确性和一致性比较,四个模型对于部分提示词的忽略是普遍情况。对于两个及以上动词,通常模型只会关注其中一个,侧重选择哪些关键词和关键信息也是考量模型理解能力的重要判断方式。
从生成视频的丰富性上,即梦和PixVerse表现较好。在一些除主体元素外的细节方面,二者都在尽量扩充内容,尤其是即梦对光线光影颇有理解。反观可灵,在这部分则相对保守,主要以保证主体元素和动作不出差错为主要聚焦。
从使用成本上,目前四个模型均可以免费或付费使用。具体来看,截至测评日,清影可以无限量使用,可灵、即梦和PicVerse则采用每日赠送积分点数的方式供用户体验。除此之外,每家的付费机制各有侧重。
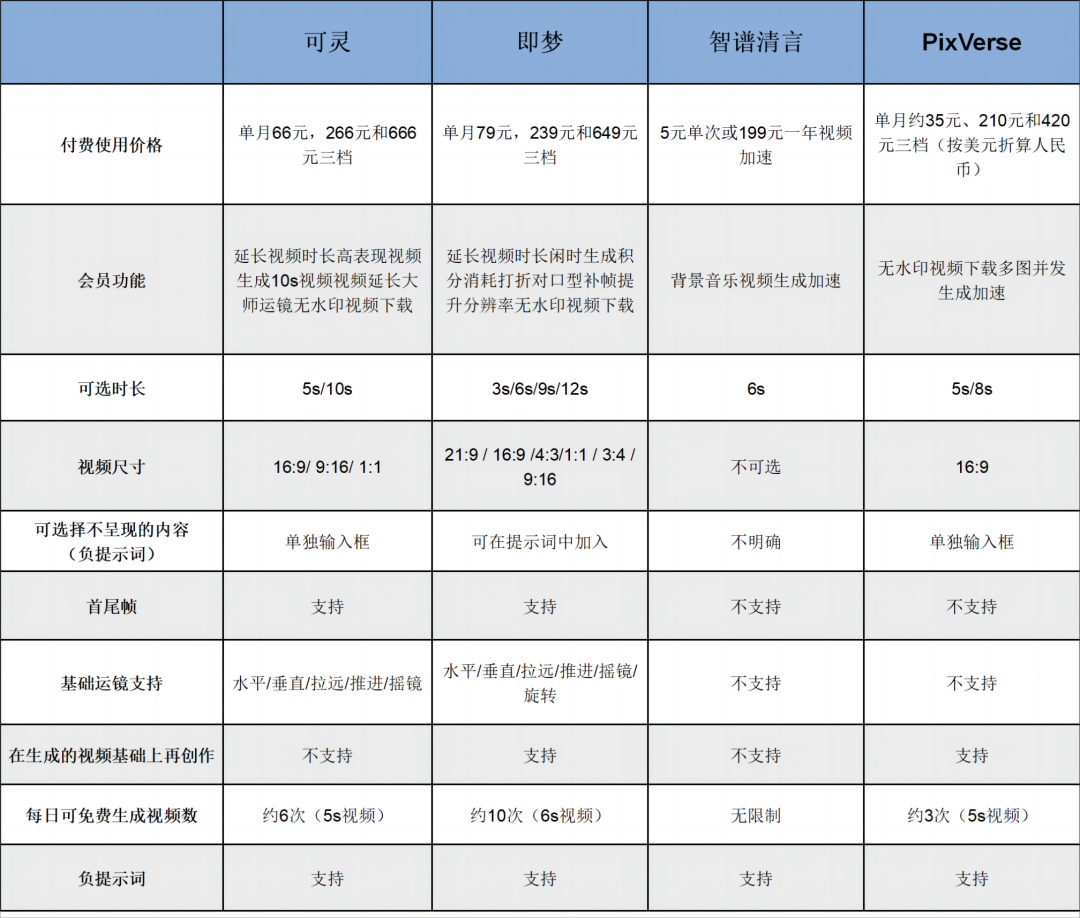
四个头部AI视频生成模型对比表
从生成速度上,我们同步实测了几个模型的生成速度,得到如下结果:
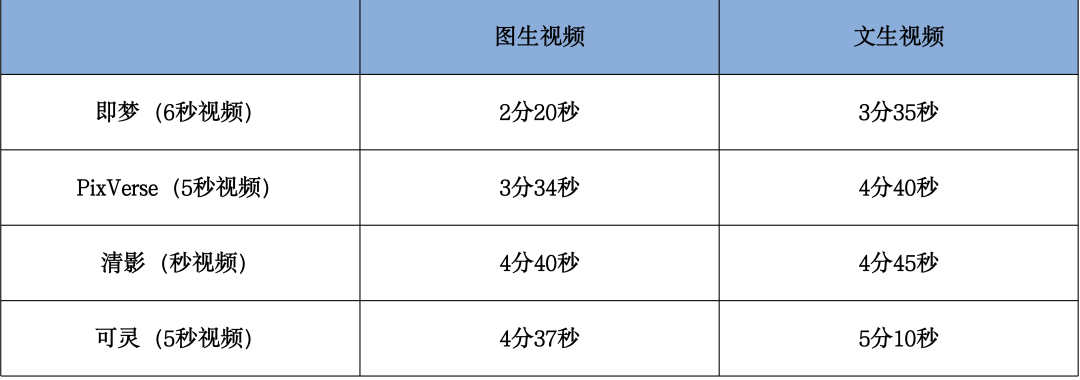
四个头部AI视频生成模型生成速度对比表(数据测试时间为8月3日上午11时)
从交互来看,在注册登录门槛上,清影仅采用手机验证码注册登录,相对简单;可灵支持手机验证码和快手账号两种登录方式,默认使用手机验证码;PixVerse则遵循海外主流产品的登录方式,提供谷歌、Discord绑定和邮箱三种登录方式;即梦带有一贯的字节系产品特色,比如在电脑端使用产品之前,需要先下载抖音才能扫码登录,当然也可以选择使用手机验证码登录,但又必须授权抖音验证。
在页面布局上,PixVerse采用纯英文界面,右上角为账户等个人信息,左侧为功能性按钮,界面交互非常简单,可调节参数也并不多,主要是正向提示词、负提示词,模型选择,时长,画面比例等。
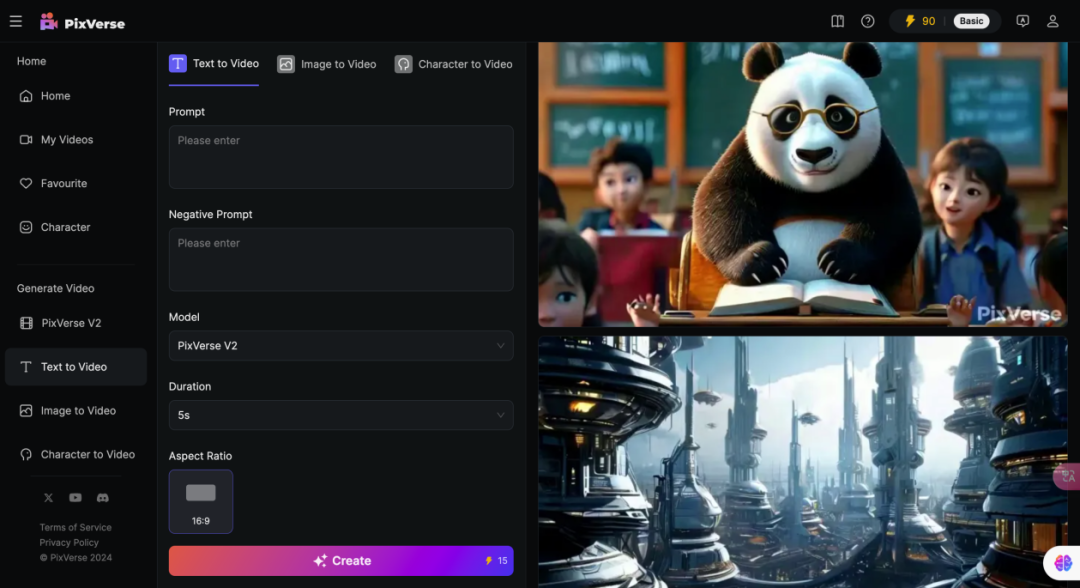
可灵的页面布局也类似,使用传统操作台界面,右上角为账户信息,左侧为调试台,中间为预览窗口,右侧为历史记录,动线流畅。可调节等参数包括正向提示词、创意想象力/创意相关性,生成模式、时长、视频比例、运镜、负提示词等。
智谱清言将AI生成视频作为整个平台的一个子功能,嵌入到平台看板中,因此在界面布局上稍显杂乱。界面共分为四个部分,最左侧是平台的功能模块,再到历史记录、视频预览,对于生成视频可操作性不高。最右侧才是控制台,仅有提示词输入,视频风格、情感氛围和运镜方式可以选择,需要用户自行探索部分隐性功能,有一定学习门槛。
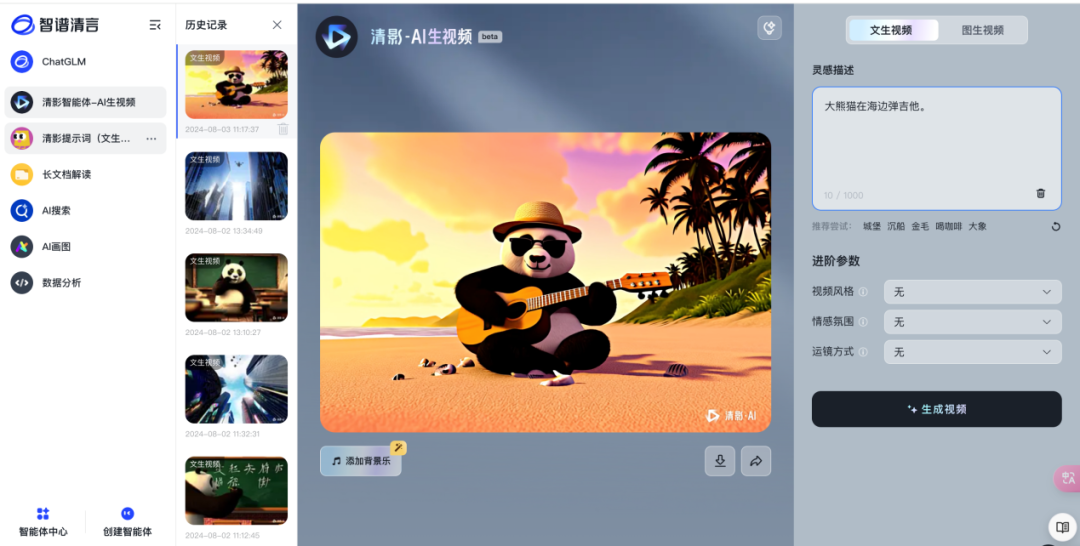
即梦模型主界面简洁,总体色调和布局承袭剪映的风格,分为左侧调试和右侧预览两部分,调试部分与其他模型大同小异。在右侧预览部分,对生成的视频可以实现延长时长、对口型、补帧、提升分辨率等会员功能,用于对生成视频的调整,也符合用户工作流习惯。
测评观察
总体使用下来,「科技新知」个人的感受是产品使用不及预期,颇有雷声大雨点小之意。就「科技新知」的测试体验而言,几款模型中体验最好的是可灵,不论是文生视频还是图生视频,相对来说都比较丝滑。对新手用户来说,不需要掌握非常复杂的提示词技巧,仅按照模型操作界面的提示,使用纯自然语言就能够达到相对满意的效果。另一方面,生成的视频在细节(比如手部)方面处理得较平滑,失误率较少。对于现阶段生成视频通常需要“抽卡”(碰运气)的赛道常态来说,减少失误率就意味着提升质量。
在本次测试场景的反馈中,即梦和PixVerse生成的视频质量相对不稳定,一定程度上表现出了模型稳定性还有待提升。而清影模型,不知是否因为训练素材的原因,生成的视频总是带有浓郁的色彩和卡通风格,让人不由想起B站“学了五年动画的朋友”系列。
技术的发展固然鼓舞人心。除了速度提升以外,不少AI视频生成模型已经初步具备了“理解”世界的能力。即在视频生成时可以理解物体运动过程中的物理世界,也能预测视频下一步可能发生什么。
但在实际应用层面,这类大模型的局限也很显然。5到10秒的可选视频长度对于用户来说稍显尴尬,很难进行任何故事性创作。目前最匹配的领域,或许只能是制作一些表情包或梗图二次创作。企业并非没有意识到问题,只是现实很骨感——长度限制是由开发成本导致的。现阶段在AI视频生成赛道上,玩家比的不只是技术,还有资金。为了“回血”,平台纷纷设计了会员机制,怎奈花的比挣的多得多。
据调查机构 Factorial Funds 的数据,以 Sora 为例,它 30 亿参数(主流猜测 )的训练成本,比 1.8 万亿参数的 GPT-4 还要多。这还只是训练,实际使用的推理成本要更多。国内有 AI 企业做过一个折算,生成一个差不多两分钟的视频,企业的成本是 180 元。收取的会员制费用相对于其研发成本来说简直是九牛一毛。
从这个层面看,像抖音、快手这类拥有短视频平台的玩家自带天然优势。一方面,其训练数据并不缺乏,另一方面,自身的海量用户也使企业更容易实现商业化路径的闭环。但变现门槛也无法忽视。设想一下,如果只是一名普通的C端用户,除了一开始的新鲜劲儿,如何保证其付费率和付费意愿?
因此,成为“中国版的Sora”远不是这场AI视频大模型竞赛的终点,而恰恰只是起点。产品问世之后,谁能找到可持续的商业化之路,落地产业化应用,才是国产AI赛道的终极玩家。
作者:余寐 编辑:赛柯
来源公众号:科技新知

自从今年年初Sora露面后,国内国外都想用AI颠覆好莱坞,近期的AI视频圈更是十分热闹,产品一个接一个发布,都喊着要赶超Sora。
国外两家AI视频初创公司率先开打,旧金山人工智能科技公司Luma推出Dream Machine视频生成模型,并扔出堪称电影级别的宣传片,产品也给用户免费试用;另一家在AI视频领域小有名气的初创公司Runway,也宣布将Gen-3 Alpha模型向部分用户开启测试,称能将光影这样的细节生产出来。
国内也不甘示弱,快手推出的可灵Web端,用户能生成长达10秒的视频内容,还具备首尾帧控制和相机镜头控制功能。其原创AI奇幻短剧《山海奇镜之劈波斩浪》也在快手播出,画面均由AI生成。AI科幻短剧《三星堆:未来启示录》也在近期播出,为字节旗下的AI视频产品即梦制作。
AI视频如此快的更新速度让不少网友直呼,“好莱坞可能又要来一次大罢工了。”
如今在AI视频赛道上,有谷歌、微软、Meta,阿里、字节、美图等国内外科技、互联网巨头,也有Runway、爱诗科技等新秀公司,据「定焦」不完全统计,仅国内,便有约20家公司推出了自研AI视频产品/模型。
头豹研究院数据显示,2021年中国AI视频生成行业的市场规模为800万元,预计2026年,这一市场规模将达到92.79亿元。不少业内人士相信,2024年生成视频赛道会迎来Midjourney时刻。
全球的Sora们发展到什么阶段了?谁最强?AI能干掉好莱坞吗?
1 围攻Sora:产品虽多,能用的少
AI视频赛道推出的产品/模型不少,但真正能让大众使用的十分有限,国外的突出代表便是Sora,半年过去了还在内测,仅对安全团队和一些视觉艺术家、设计师和电影制作人等开放。国内情况也差不多,阿里达摩院的AI视频产品“寻光”、百度的AI视频模型UniVG都在内测阶段,至于目前正火的快手可灵,用户想使用也需要排队申请,这已经刨去了一大半产品。
剩下可使用的AI视频产品中,一部分设置了使用门槛,用户需要付费或懂一定技术。比如潞晨科技的Open-Sora,如果不懂一点代码知识,使用者便无从下手。
「定焦」整理国内外公布的AI视频产品发现,各家的操作方式和功能差不多,用户先用文字生成指令,同时选择画幅大小、图像清晰度、生成风格、生成秒数等功能,最终点击一键生成。
这些功能背后的技术难度不同。其中最难的是,生成视频的清晰度和秒数,这也是AI视频赛道各家在宣传时比拼的重点,背后与训练过程中使用的素材质量和算力大小密切相关。
AI研究者Cyrus告诉「定焦」,目前国内外大多数AI视频支持生成480p/720p,也有少部分支持1080p的高清视频。
他介绍,高质量素材越多,算力越高,训练出来的模型能生成更高质量的视频,但不代表有高质量的素材算力,就能生成高质量素材。而用低分辨率素材训练的模型,若要强行生成高分辨视频,会出现崩坏或者重复,比如多手多脚。这类问题可以通过放大、修复和重绘之类的方式解决,不过效果和细节一般。
很多公司也把生成长秒数当卖点。
国内大部分AI视频支持2-3秒,能达到5-10秒算是比较强的产品,也有个别产品很卷,比如即梦最高长达12秒,不过大家都不及Sora,它曾表示最长能生成一段60秒的视频,但由于还没有开放使用,具体表现如何无法验证。
光卷时长还不够,生成的视频内容也得合理。石榴AI首席研究员张恒对「定焦」表示:从技术上,可以要求AI一直输出,毫不夸张地说,哪怕生成一个小时的视频,也不是问题,但我们多数时候要的并不是一段监控视频,也不是一个循环播放的风景画动图,而是画面精美有故事的短片。
「定焦」测试了5款国内比较热的免费文生视频AI产品,分别为字节的即梦、Morph AI的Morph Studio、爱诗科技的PixVerse、MewXAI的艺映AI、右脑科技的Vega AI,给了它们一段相同的文字指令:“一个穿着红裙子的小女孩,在公园里,喂一只白色的小兔子吃胡萝卜。”
几款产品的生成速度上差不多,仅需2-3分钟,但清晰度、时长差得不少,准确度上更是“群魔乱舞” ,得到结果如下 :

艺映AI

Vega AI

即梦

Morph

Pix Verse
各家的优缺点很明显。即梦赢在时长,但生成质量不高,主角小女孩在后期直接变形,Vega AI也是相同的问题。PixVerse的画质比较差。
相比之下,Morph生成的内容很准确,但只有短短2秒。艺映画质也不错,但对文字理解不到位,直接把兔子这一关键元素弄丢了,且生成视频不够写实,偏漫画风。
总之,还没有一家产品能给到一段符合要求的视频。
2 AI视频难题:准确性、一致性、丰富性
「定焦」的体验效果和各家释放的宣传片相差很大,AI视频如果想要真正商用,还有相当长的一段路要走。
张恒告诉「定焦」,从技术角度看,他们主要从三个维度考量不同AI视频模型的水平:准确性、一致性、丰富性。
如何理解这三个维度,张恒举了个例子。
比如生成一段“两个女孩在操场看篮球比赛”的视频。
准确性体现在,一是对内容结构理解的准确,比如视频中出现的要是女孩,而且还是两个;二是流程控制的准确,比如投篮投进后,篮球要从篮网中逐渐下降;最后是静态数据建模准确,比如镜头出现遮挡物时,篮球不能变成橄榄球。
一致性是指,AI在时空上的建模能力,其中又包含主体注意力和长期注意力。
主体注意力可以理解为,在看篮球比赛的过程中,两个小女孩要一直留在画面里,不能随便乱跑;长期注意力为,在运动过程中,视频中的各个元素既不能丢,也不能出现变形等异常情况。
丰富性则是指,AI也有自己的逻辑,即便在没有文字提示下,能生成一些合理的细节内容。
以上维度,市面上出现的AI视频工具基本都没能完全做到,各家也在不断提出解决办法。
比如在视频很重要的人物一致性上,即梦、可灵想到了用图生视频取代文生视频。即用户先用文字生成图片,再用图片生成视频,或者直接给定一两张图片,AI将其连接变成动起来的视频。
“但这不属于新的技术突破,且图生视频难度要低于文生视频,”张恒告诉「定焦」,文生视频的原理是,AI先对用户输入的文字进行解析,拆解为一组分镜描述,将描述转文本再转图片,就得到了视频的中间关键帧,将这些图片连接起来,就能获得连续有动作的视频。而图生视频相当于给了AI一张可模仿的具体图片,生成的视频就会延续图片中的人脸特征,实现主角一致性。
他还表示,在实际场景中,图生视频的效果更符合用户预期,因为文字表达画面细节的能力有限,有图片作为参考,会对生成视频有所帮助,但当下也达不到商用的程度。直观上说,5秒是图生视频的上限,大于10秒可能意义就不大了,要么内容出现重复,要么结构扭曲质量下降。
目前很多宣称用AI进行全流程制作的影视短片,大部分采用的是图生视频或者视频到视频。
即梦的使用尾帧功能用的也是图生视频,「定焦」特意进行了尝试,结果如下:

在结合的过程中,人物出现了变形、失真。
Cyrus也表示,视频讲究连贯,很多AI视频工具支持图转视频也是通过单帧图片推测后续动作,至于推测得对不对,目前还是看运气。
据了解,文生视频在实现主角一致性上,各家也并非纯靠数据生成。张恒表示,大多数模型都是在原有底层DIT大模型的基础上,叠加各种技术,比如ControlVideo(哈工大和华为云提出的一种可控的文本-视频生成方法),从而加深AI对主角面部特征的记忆,使得人脸在运动过程中不会发生太大变化。
不过,目前都还在尝试阶段,即便做了技术叠加,也还没有完全解决人物一致性问题。
3 AI视频,为什么进化慢?
在AI圈,目前最卷的是美国和中国。
从《2023年全球最具影响力人工智能学者》(简称“AI 2000学者”榜单)的相关报告可以看出,2020年-2023年全球“AI 2000机构”4年累计的1071家机构中,美国拥有443家,其次是中国,有137家,从2023年“AI 2000学者”的国别分布看,美国入选人数最多,共有1079人,占全球总数的54.0%,其次是中国,共有280人入选。
这两年,AI除了在文生图、文生音乐的方面取得较大进步之外,最难突破的AI视频也有了一些突破。
在近期举办的世界人工智能大会上,倚天资本合伙人乐元公开表示,视频生成技术在近两三年取得了远超预期的进步。新加坡南洋理工大学助理教授刘子纬认为,视频生成技术目前处于GPT-3 时代,距离成熟还有半年左右的时间。
不过,乐元也强调,其技术水平还是不足以支撑大范围商业化,基于语言模型开发应用所使用的方法论和遇到的挑战,在视频相关的应用领域也同样适用。
年初Sora的出现震惊全球,它基于transformer架构的新型扩散模型DiT再做扩散、生成的技术突破,提高了图像生成质量和写实,使得AI视频取得了重大突破。 Cyrus表示,目前国内外的文生视频,大多数都沿用的是类似技术。

图源 / Sora官网
此刻,大家在底层技术上基本一致,虽然各家也以此为基础寻求技术突破,但更多卷的是训练数据,从而丰富产品功能。
用户在使用字节的即梦和Morph AI的Morph Studio时,可选择视频的运镜方式,背后原理便是数据集不同。
“以往各家在训练时使用的图片都比较简单,更多是对图片存在哪些元素进行标注,但没有交代这一元素用什么镜头拍摄,这也让很多公司发现了这一缺口,于是用3D渲染视频数据集补全镜头特征。”张恒表示,目前这些数据来自影视行业、游戏公司的效果图。
「定焦」也尝试了这一功能,但镜头变化不是很明显。
Sora们之所以比GPT、Midjourney们发展得慢,是因为又搭了一个时间轴,且训练视频模型比文字、图片更难。“现在能用的视频训练数据,都已经挖掘殆尽,我们也在想一些新办法制造一系列可以拿来训练的数据。”张恒说。
且每个AI视频模型都有自己擅长的风格,就像快手可灵做的吃播视频更好,因为其背后有大量这类数据支撑。
石榴AI创始人沈仁奎认为,AI视频的技术有Text to video(文本转视频),Image to video(图片转视频),Video to video(视频转视频),以及Avatar to video(数字人),能定制形象和声音的数字人,已经运用到了营销领域,达到了商用程度,而文生视频还需要解决精准度和可控度问题。
此刻,无论是由抖音和博纳合作的AI科幻短剧《三星堆:未来启示录》,还是快手原创的AI奇幻短剧《山海奇镜之劈波斩浪》,更多是大模型公司主动找影视制作团队进行合作,有推广自家技术产品的需求,且作品也没有出圈。
在短视频领域,AI还有很长的路要走,干掉好莱坞了的说法更为时尚早。
作者:王璐,编辑:魏佳
来源公众号:定焦
]]>
Sora,OpenAI的人工智能AI生成式视频大模型,在2024年2月15日一经发布,就引发了全球关注,硅谷AI视频论文作者(非Sora)这样评价:相当好,这是毋庸置疑的No.1。

Sora好在哪里?生成式AI视频的发展挑战在哪里?OpenAI的视频模型一定是正确的路线吗?所谓的“世界模型”达成共识了吗?这期视频,我们通过与硅谷一线AI从业人员的采访,深度聊聊生成式AI视频大模型的不同派系发展史,大家的争议和未来路线。
AI生成视频这个题我们其实去年就想做了,因为当时跟很多人聊天,包括跟VC投资人聊的时候,发现其实大家对AI视频模型和ChatGPT这种大语言模型的区别并不是很清楚。但是为啥没做呢,因为在去年年底,市场中做得最好的也就是runway这家公司旗下的Gen1和Gen2两种视频生成视频以及文字生成视频的功能,但我们生成出来的效果… 有点一言难尽。
比如说,我们用runway生成的一个视频,prompt提示词是”super mario walking in a desert”(超级马里奥漫步于沙漠中),结果出来的视频是这样的:

怎么看怎么像马里奥跳跃在月球上。无论是重力还是摩擦力,物理学在这段视频里好像突然不复存在。
然后我们尝试了另外一个提示词,“A group of people walking down a street at night with umbrellas on the windows of stores.”(雨夜的大街上,一群人走在商铺窗户檐的伞下)这段提示词也是一个投资人Garrio Harrison尝试过的,结果出来的视频,是这样的:

你看这空中漂浮的雨伞,是不是很诡异… 但这已经是去年代表着最领先技术的runway了。之后华人创始人Demi Guo创立的Pika Labs火了一阵,被认为比runway效果稍好一些,但依然受制于3-4秒的长度显示,并且生成的视频仍然存在视频理解逻辑、手部构图等缺陷问题。
所以,在OpenAI发布Sora模型之前,生成式AI视频模型并没有像ChatGPT、Midjourney这样的聊天和文生图应用一样引发全球关注,很大原因就是因为生成视频的技术难度非常高,视频是二维空间+时间,从静态到动态,从平面到不同时间片段下的平面显示出的立体效果,不但需要强大的算法和算力,还需要解决一致性、连贯性、物理合理性、逻辑合理性等等一系列的复杂问题。

所以,生成式视频大模型这个选题,一直都在我们硅谷101的选题单上,但一直拖着没做,想等生成式AI视频模型有一个重大突破的时候,我们再来做这个选题,结果没想到,这么快,这个时刻,就来了。
01 生成式AI视频的ChatGPT时刻?
Sora的展示,毫无疑问是吊打此前的runway和pika labs的。
首先,最大的突破之一,很直观的就是:生成视频长度大大的延长了。之前,runway和pika都只能生成出3-4秒的视频,太短了,所以之前能出圈的AI视频作品,就只有一些快节奏的电影预告片,因为其它需要长一些素材的用途根本无法被满足。

而在runway和pika上,如果需要更长的视频,你就需要自己不断提示叠加视频时长,但我们视频后期剪辑师Jacob就发现,这会出现一个大问题。
Jacob,硅谷101视频后期剪辑师:
痛点就是你在不断往后延长的时候,它后面的视频会出现变形,就会导致前后视频画面的不一致,那这段素材就用不了了。
而Sora最新展示的论文和demo中表示,可以根据提示词,直接生成1分钟左右的视频场景。与此同时,Sora会兼顾视频中人物场景的变换以及主题的一致性。这让我们的剪辑师看了之后,也直呼兴奋。

Jacob,硅谷101视频后期剪辑师:
(Sora)其中有一个视频是一个女孩走在东京的街头… 对我来说,这个是很厉害的。所以,就算在视频动态的运动情况下,随着空间的移动和旋转,Sora视频中出现的人物和物体会保持场景一致性的移动。
第三,Sora可以接受视频,图像或提示词作为输入,模型会根据用户的输入来生成视频,比如,公布出demo中的一朵爆开的云。这意味着,Sora模型可以基于静态图像来制作动画,做到在时间上向前或者向后来扩展视频。

第四,Sora可以读取不同的无论是宽屏还是垂直视频、进行采样,也可以根据同一个视频去输出不同尺寸的视频,并且保持风格稳定,比如说这个小海龟的样片。这其实对我们视频后期的帮助是非常大的,现在Youtube和B站等1920*1080p横屏视频,我们需要重新剪成垂直1080*1920的视频来适配抖音和Tiktok等短视频平台,但可以想象,之后也许就能通过Sora一键AI转换,这也是我很期待的功能。
第五,远距离相干性和时间连贯性更强了。此前,AI生成视频有个很大的困难,就是时间的连贯性,但Sora能很好的记住视频中的人和物体,即使被暂时挡住或移出画面,之后再出现的时候也能按照物理逻辑地让视频保持连贯性。比如说Sora公布的这个小狗的视频,当人们走过它,画面被完全挡住,再出现它的时候,它也能自然地继续运动,保持时间和物体的连贯。

第六,Sora模型已经可以简单地模拟世界状态的动作。比如说,画家在画布上留下新的笔触,这些笔触会随着时间的推移而持续存在,或者一个人吃汉堡的时候会留下汉堡上的咬痕。有比较乐观的解读认为,这意味着模型具备了一定的通识能力、能“理解”运动中的物理世界,也能够预测到画面的下一步会发生什么。

因此,以上这几点Sora模型带来的震撼更新,极大地提高了外界对生成式AI视频发展的期待和兴奋值,虽然Sora也会出现一些逻辑错误,比如说猫出现三只爪子,街景中有不符合常规的障碍物,人在跑步机上的方向反了等等,但显然,比起之前的生成视频,无轮是runway还是pika还是谷歌的videopoet,Sora都是绝对的领先者,而更重要的是,OpenAI似乎通过Sora想证明,堆算力堆参数的“大力出奇迹”方式也可以适用到生成式视频上来,并且通过扩散模型和大语言模型的整合,这样的模型新路线,来形成所谓的“世界模型”的基础,而这些观点,也在AI届引发了极大的争议和讨论。
接下来,我们就来试图回顾一下生成式AI大模型的技术发展之路,以及试图解析一下,Sora的模型是怎么运作的,它到底是不是所谓的“世界模型”?
02 扩散模型技术路线: Google Imagen,Runway,Pika Labs
AI生成视频的早期阶段,主要依赖于GAN(生成式对抗网络)和VAE(变分自编码器)这两种模型。但是,这两种方法生成的视频内容相对受限,相对的单一和静态,而且分辨率往往不太行,完全没办法进行商用。所以这两种模型我们就先不讲了哈。

之后,AI生成视频就演变成了两种技术路线,一种是专门用于视频领域的扩散模型,一种则是Transformer模型。我们先来说说扩散模型的路线,跑出来的公司就有Runway和Pika Labs等等。
03 什么是扩散模型?
扩散模型的英文是Diffusion Model。很 多人不知道,如今最重要的开源模型Stable Diffusion的原始模型就是由Runway和慕尼黑大学团队一起发布的,而Stable Diffusion本身也是R unway核心产品—视频编 辑器Gen-1和Gen-2背后的底层技术基础。

Gen-1模型在2023年2月发布,允许大家通过输入文本或图像,改变原视频的视觉风格,例如将手机拍摄的现实街景变成赛博世界。而在6月,runway发布Gen-2,更近一步能将用户输入的文本提示直接生成为视频。
扩散模型的原理,大家一听这个名字“扩散模型”,就能稍微get到:是通过逐步扩散来生成图像或视频。为了更好的给大家解释模型原理,我们邀请到了之前Meta Make-A-Video模型的论文作者之一、目前在亚马逊AGI团队从事视频生成模型的张宋扬博士来给我们做一个解释。

张宋扬博士,Meta Make-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
之所以最开始这篇论文之所以用扩散这个名字,是源于一个物理现象,就是说比如说我们把墨水滴到一杯水里面去,墨水它会散开,这个东西叫扩散。这个过程本身物理上是不可逆的,但是我们AI可以学习这么一个过程,把这个过程给逆过来。它类比到图片里面来说,就是一个图片,它是不断加噪声不断加噪声,然后它会变成一个类似于马赛克这样的一个效果。它是一个纯噪声的一张图片。然后我们学习怎么把这个噪点变成一张原始的图片。
我们训练这么样的一个模型,直接去一步完成的话,这个可能会很难,它分成了很多步,比如我分成1000步,比如说我加一点点噪声,它能够还原出去噪声后是什么样子,然后噪声加得比较多的时候,我该怎么去用这个模型怎么去预测噪声?就是它分了很多步,然后逐渐地去把这噪声慢慢地去掉,它迭代式地把这个噪声慢慢给去掉。比如说原来是一个水跟墨已经完全混合在一起了,你想办法怎么去预测它,一步一步它如何再变回之前的那一滴墨水的样子。就是它是一个扩散的一个逆过程。

张宋扬博士解释得很形象,扩散模型的核心思想是通过不断地向原始噪声引入随机性,逐步生成逼真的图像或视频。在而这个过程分成了四步:
1)初始化:扩散模型开始于一个随机的噪声图像或视频帧作为初始输入。
2)扩散过程(也被称为前向过程forward process):扩散过程的目标是让图片变得不清晰,最后变成完全的噪声。
3)反向过程(reverse process,又被称为backward diffusion):这时候我们会引入“神经网络”,比如说基于卷积神经网络(CNN)的UNet结构,在每个时间步预测“要达到现在这一帧模糊的图像,所添加的噪声”,从而通过去除这种噪声来生成下一帧图像,以此来形成图像的逼真内容。
4)重复步骤:重复上述步骤直到达到所需的生成图像或视频的长度。

以上是 video to video或者是picture to video的生成方式,也是runway Gen1的大概底层技术运行方式。如果是要达到输入提示词来达到text to video,那么就要多加几个步骤。

比如说我们拿谷歌在2022年中旬发布的Imagen模型来举例:我们的提示词是a boy is riding on the Rocket,骑着火箭的男孩。这段提示词会被转换为tokens(标记)并传递给编码器text encoder。谷歌 IMAGEN模型接着用T5-XXL LLM编码器将输入文本编码为嵌入(embeddings)。这些嵌入代表着我们的文本提示词,但是以机器可以理解的方式进行编码。
之后这些“嵌入文本”会被传递给一个图像生成器image generator,这个图像生成器会生成64×64分辨率的低分辨率图像。之后,IMAGEN模型利用超分辨率扩散模型,将图像从64×64升级到256×256,然后再加一层超分辨率扩散模型,最后生成与我们的文本提示紧密结合的 1024×1024 高质量图像。
简单总结来说,在这个过程中,扩散模型从随机噪声图像开始,在去噪过程中使用编码文本来生成高质量图像。
04 扩散模型优劣势
而生成视频为什么要比生成图片困难这么多?
张宋扬博士,Meta Make-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
它的原理实际上还是一样的,只不过唯一一个区别就是多了一个时间轴。就是刚刚我们说的图片,它是一个2D的,它是高度跟宽度。然后视频它多一个时间轴,它就是一个3D的,它就是高度、宽度还有一个时间。然后它在学习这个扩散的逆过程的过程当中,就是相当于以前是一个2D的逆过程,现在变成一个3D的逆过程,就是这么一个区别。

所以说图片上的存在的问题,比如说像这些生成的人脸它是不是真实啊?那我们如果图片存在这样的问题,我们视频也一样会存在这样的问题。对于视频来说,它有一些它有些独特的一些问题,就比如说刚才像你说的这个画面的主体是不是保持一致的?我觉得目前对于像风景这样的,其实效果都还可以,然后但是如果涉及到人的话,因为人的这些要求可能会更精细,所以说人的难度会更高,这是一个问题。然后还有一个目前的难点,我觉得也是大家都在努力的一个方向,就是怎么把视频变得更长。因为目前来说的话,只生成2秒、3秒、4秒这样的视频,其实远远满足不了现在的应用场景。

扩散模型比起之前的GAN等模型来说,有三个主要的优点:
第一,稳定性:训练过程通常更加稳定,不容易陷入模式崩溃或模式塌陷等问题。
第二,生成图像质量:扩散模型可以生成高质量的图像或视频,尤其是在训练充分的情况下,生成结果通常比较逼真。
第三,无需特定架构:扩散模型不依赖于特定的网络结构,兼容性好,很多不同类型的神经网络都可以拿来用。
然而,扩散模型也有两大主要缺点,包括:
首先,训练成本高:与一些其他生成模型相比,扩散模型的训练可能会比较昂贵,因为它需要在不同噪声程度的情况下学习去燥,需要训练的时间更久。
其次,生成花费的时间更多。因为生成时需要逐步去燥生成图像或视频,而不是一次性地生成整个样本。
张宋扬博士,Meta Make-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
就是我们其实现在无法生成长的视频一个很重要原因就是,我们的显存是有限的。生成一张图片可能占用一部分的显存,然后你如果生成16张图片,就可能差不多把这显存给占满了。当你需要生成更多张图片的时候,你就得想办法怎么去,既考虑之前已经生成的这些信息,然后再去预测后面该生成什么样的信息。它首先在模型上面就提了一个更高的要求,当然算力上面也是一个问题,就是获取过很多年之后,我们的显存会非常的大,可能我们也就不存在这样的问题了,也是有可能的,但是就目前来说,当下我们是需要一个更好的一个算法,但是如果有更好硬件可能这个问题就不存在。
所以,这注定了目前的视频扩散模型本身可能不是最好的算法,虽然runway和PikaLabs等代表公司一直在优化算法。
我们接下来,聊聊另外一个派别:基于Transformer架构的大语言模型生成视频技术路线。
05 大语言模型生成视频技术路线(VideoPoet)
最后, 谷歌在2023年12月底发布了基于大语言模型的生成式AI视频模型VideoPoet,这在当时被视为生成视频领域中,扩散模型之外的另外一种解法和出路。它是这么个原理呢?
大语言模型如何生成视频?
大语言模型生成视频是通过理解视频内容的时间和空间关系来实现的。谷歌的VideoPoet是一个利用大语言模型来生成视频的例子。这个时候,让我们再次请出生成式AI科学家张宋扬博士,来给我们做一个生动的解释。
张宋扬博士,Meta Make-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
然后大语言模型这个东西,原理上完全不一样,它最一开始是用在文本上面,用在文本上面就是说我预测下一个单词是什么,就比如说“我爱说实话”,然后最后一个“我爱说实”,然后最后一个字是什么?你猜是什么字?然后可能你给的这些前面的字越多,你可能越容易猜到后面。但是如果你给的字比较少,你可能发挥空间会更多,它是这么样一个过程。

然后这个思路带到了视频当中,那就是我们可以学一个图片的词汇,或者说是视频的词汇。就是说我们可以把图片横着切,比如说横着切16刀,竖着切16刀,然后把每一个小方块、小格子当成一个词,然后把它输到这个大语言模型当中,让他们学习。比如说之前你已经有一个很好的一个大语言模型了,然后你去学习怎么大语言模型的这些词跟这些文本的词或者视频的词进行一个交互,它们之间的进行一个关联,是一个什么样的关联?你去学一些这个东西,然后这样的话,我们就可以利用这些大语言模型,让它可以去做一些视频的任务,或者是文本的一些任务。
简单来说,基于大语言模型的Videopoet是这样运作的:
1)输入和理解:首先Videopoet接收文本,声音,图片,深度图,光流图,或者有待编辑的视频作为输入。
2)视频和声音的编码:因为文本天然就是离散的形式,大语言模型自然而然就要求输入和输出必须是离散的特征。然而视频和声音是连续量,为了让大语言模型也能让图片,视频或者声音作为输入和输出,这里Videopoet将视频和声音编码成离散的token。在深度学习中,token是一个非常重要的概念, 它是指一组符号或标识符,用于表示一组数据或信息中的一个特定元素。在Videopoet的例子中,通俗一点可以理解成视频的单词和声音的单词。

3)模型训练和内容生成:有了这些Token词汇,就可以根据用户给的输入,像学习文本token那样,训练一个Transformer去学习逐个预测视频的token,模型就会开始生成内容。对于视频生成,这意味着模型需要创建连贯的帧序列,这些帧不仅在视觉上符合逻辑,还要在时间上保持连续性。
4)优化和微调:生成的视频可能需要进一步的优化和微调,以确保质量和连贯性。这可能包括调整颜色、光照和帧之间的过渡等。VideoPoet利用深度学习技术来优化生成的视频,确保它们既符合文本描述,又在视觉上吸引人。
5)输出:最后,生成的视频会被输出,供最终用户观看。

但是,大语言模型生成视频的路线,也是优点和缺点并存的。
06 大语言模型生成视频优劣势
先来说说优点:
1)高度理解能力:基于Transformer架构的大语言模型能够处理和理解大量的数据,包括复杂的文本和图像信息。这使得模型能具有跨模态的理解和生成能力,能够很好学到文本和图片视频不同模态之间关联的能力。这使得它们在将文本描述转换成视频内容时,能够生成更准确和相关的输出。
2)处理长序列数据:由于自注意力机制,Transformer模型特别擅长处理长序列数据,这对于视频生成尤其重要,因为视频本质上是长序列的视觉表示。
3)Transformer的可扩展性:通常来说模型越大,拟合的能力就越强。但当模型大到一定程度时,卷积神经网络性能受模型增大带来的增益会放缓甚至停止,而Transformer仍能持续增长。Transformer在大语言模型已经证明了这一点,如今在图片视频生成这一领域也逐渐崭露头角。

再来说说缺点:
1)资源密集型:用大语言模型生成视频,特别是高质量视频,需要大量的计算资源,因为用大语言模型的路线是将视频编码成token,往往会比一句话甚至一段话的词汇量要大的多,同时,如果一个一个的去预测,会让时间的开销非常大。也就是说,这可能使得Transformer模型的训练和推理过程变得昂贵和时间消耗大。

张宋扬博士,Meta Make-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
有一个问题我觉得挺本质的,就是transformer它不够快,这个是很本质的一个问题,因为transformer它一个小方块一个小方块地预测,扩散模型直接一张图就出来了,所以transformer肯定会比较慢的。
陈茜,硅谷101视频主理人:
太慢了有一个具象的一个数据吗?就是能慢多少?
张宋扬博士,Meta Make-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
就比如说我直接出一张图,diffusion比如出一张图就是1,它也需要一些迭代过程。然后比如说我用四步,它就是四步去生成出来,咱就是4。现在目前做得好的话,四步我看有做的效果还是不错的。然后但是你要是用transformer的话,比如说你画16*16的方格,那就是16*16,那就等于256了,就是那个速度。
4是相当于我做去噪迭代了四次。然后transformer的话,它是相当于我去预测一张图片,比如说是16*16的话,我就预测256个词。他们的量纲肯定不一样,但是他们的复杂度你是可以看出来的。就是diffusion模型,它的复杂度是一个常数集。但是transformer的那个复杂度,它实际上是一个宽度x高度,复杂度会不一样。所以说从复杂度角度来说,肯定是扩散模型会更优一些。然后具体我觉得这东西可能你如果是图片越大的话,分辨率越高的话,transformer的问题可能会越大。
Transformer模型的另外一些问题还包括:
2)质量波动:尽管Transformer模型能够生成创造性的视频内容,但输出的质量可能不稳定,特别是对于复杂的或未充分训练的模型。
3)数据依赖性:Transformer模型的性能在很大程度上取决于训练数据的质量和多样性。如果训练数据有限或有偏差,生成的视频可能无法准确反映输入的意图或在多样性上存在限制。
4)理解和逻辑限制:虽然Transformer模型在理解文本和图像内容方面取得了进步,但它们可能仍然难以完全把握复杂的人类情感、幽默或细微的社会文化信号,这可能会影响生成视频的相关性和吸引力。
5)伦理和偏见问题:自动视频生成技术可能会无意中复制或放大训练数据中的偏见,导致伦理问题。
不过说到第五点,我突然想起来最近的这么一个新闻,说谷歌的多模态大模型Gemini中,无论你输入什么人,出来的都是有色人种,包括美国开国元勋,黑人女性版本的教皇,维京人也是有色人种,生成的Elon Musk也是黑人。

这背后的原因可能是谷歌为了更正Transformer架构中的偏见,给加入了AI道德和安全方面的调整指令,结果调过头了,出了这个大乌龙。不过这个事情发生在OpenAI发布了Sora之后,确实又让谷歌被群嘲了一番。
不过,业内人士也指出,以上的这五点问题也不是transformer架构所独有的,目前何生成模型都可能存在这些问题,只是不同模型在不同方向的优劣势稍有不同。

所以,到这里总结一下,扩散模型和Transformer模型生成视频都有不甚令人满意的地方,那么,身为技术最为前沿的公司OpenAI他们是怎么做的呢?诶,也许你猜到了,这两模型各有千秋,我把它们结合在一起,会不会1+1>2呢?于是,Sora,也就是扩散模型和Transformer模型的结合。
07 Sora的扩散+大语言模型:1+1>2?
说实话,目前外界对Sora的细节还是未知的,现在也没有对公众开放,连waitinglit都没有开放,只邀请了业界和设计界的极少数人来使用,产出的视频也在网上都公开了。对于技术,更多是基于OpenAI给出的效果视频的猜测和分析。OpenAI在发布Sora当天给出了一个比较模糊的技术解释,但中间很多技术细节是缺失的。

但我们先从Sora公开的这篇技术解析,来看看OpenAI的扩散+大语言模型技术路线是如何操作的。
Sora在开头就说得很清楚:OpenAI在可变持续时间、分辨率和宽高比的视频和图像上“联合训练文本条件扩散模型”(text-conditional diffusion models)。同时,利用对视频和图像潜在代码的时空补丁(spacetime patches)进行操作的Transformer架构。
所以,Sora模型的生成的步骤包括:
第一步:视频压缩网络
在基于大语言模型的视频生成技术中,我们提到过把视频编码成一个一个离散的token,这里Sora也采用了同样的想法。视频是一个三维的输入(两维空间+一维时间),这里将视频在三维空间中均分成一个一个小的token,被OpenAI称为“时空补丁”(spacetime patches)。

第二步:文本理解
因为Sora有OpenAI文生图模型DALLE3的加持,可以将许多没有文本标注的视频自动进行标注,并用于视频生成的训练。同时因为有GPT的加持,可以将用户的输入扩写成更加详细的描述,使得生成的视频获得更加贴合用户的输入,并且transformer框架能帮助Sora模型更有效地学习和提取特征,获取和理解大量的细节信息,增强模型对未见过数据的泛化能力。

比如说,你输入“一个卡通袋鼠在跳disco”,GPT会帮助联想说,得在迪厅,带个墨镜,穿个花衬衫,灯光闪耀,背后还有一堆各种动物,在一起蹦跶,等等等等来发挥联想能力解释输入的prompt。所以,GPT能展开的解释和细节丰富程度,将会决定Sora生成得有多好。而GPT模型就是OpenAI自家的,不像其它AI视频startup公司需要调用GPT模型,OpenAI给Sora的GPT架构的调取效率和深广度,肯定是最高的,这可能也是为什么Sora会在语义理解上做得更好。

第三步:Diffusion Transformer成像
Sora采用了Diffusion和Transformer结合的方式。
之前我们在基于大语言模型的视频生成技术中提到过Transformer具有较好的可拓展性。意思就是说Transformer的结构会随着模型的增大,效果会越来越好。这一特性并不是所有模型都具备的。比如当模型大到一定程度时,卷积神经网络性能受模型增大带来的增益会放缓甚至停止,而Transformer仍能持续增长。

很多人会注意到,Sora在保持画面物体的稳定性、一致性、画面旋转等等,都表现出稳定的能力,远超runway,Pika,Stable Video等基于Diffusion模型所呈现的视频模型。
还记得我们在说扩散模型的时候也说道:视频生成的挑战在于生成物体的稳定性一致性。这是因为,虽然Diffusion是视频生成技术的主流,但之前的工作一直局限在基于卷积神经网络的结构,并没有发挥出Diffusion全部潜力,而Sora很巧妙的结合了Diffusion和Transformer这两者的优势,让视频生成技术获得了更大的提升。
更深一步说,Sora生成的视频连续性可能是通过Transformer Self- Attention自注意力机制获得的。Sora可以将时间离散化,然后通过自注意力机制理解前后时间线的关系。而自注意力机制的原理就是每个时间点和其他所有时间点产生联系,这是Diffusion Model所不具备的。

目前外界有一些观点猜测,在我们之前说到的扩散模型的第三步骤中,Sora选择将U-Net架构替换成了Transformer架构。这让Diffusion扩散模型作为一个画师开始逆扩散、画画的时候,在消除噪音的过程中,能根据关键词特征值对应的可能性概率,在OpenAI海量的数据库中,找到更贴切的部分,来进行下笔。
我在采访另一位AI从业者的时候,他用了另外一个生动的例子解释这里的区别。他说:“扩散模型预测的是噪音,从某个时间点的画面,减去预测的噪音,得到的就是最原始没有噪音的画面,也就是最终生成的画面。这里更像是雕塑,就像米开朗基罗说的,他只是遵照上帝的旨意将石料上不应该存在的部分去掉,最终他才从中创造出伟大的雕塑作品。而Transformer通过自注意力机制,理解时间线之间的关联,让这尊雕塑从石座上走了下来。”是不是还挺形象的?

最后,Sora的Transformer+Diffusion Model将时空补丁生成图片,然后图片再拼接为视频序列,一段Sora视频就生成了。
说实话,Transformer加扩散模型的方法论并不是OpenAI独创的,在OpenAI发布Sora之前,我们在和张宋扬博士今年一月份采访的时候,他就已经提到说,Transformer加扩散模型的方式已经在行业中开始普遍的被研究了。

张宋扬博士,Meta Make-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
目前又能看到一些把transformer的模型做到跟diffusion结合,然后效果可能也不差,甚至可能论文里面有些说的可能会更好。所以说这个东西我不确定以后模型会怎么发展,我觉得可能是两者结合的一种方式。就是transformer他们那种,比如说它预测下一个视频,有天然的优势,就是它可以预测变成的一些东西。diffusion虽然质量高,但是diffusion目前很多做法还是生成固定帧数的。怎么把两个东西结合在一起,是一个后面会研究的一个过程。
所以,这也解释了为什么OpenAI现在要发布Sora,其实在OpenAI的论坛上,Sora方澄清说,Sora现在并不是一个成熟的产品,所以,它不是已发布的产品,也不公开,没有等候名单,也没有预计的发布日期。

外界有分析认为,Sora还不成熟,OpenAI算力也不一定能承受Sora被公开,同时还有公开之后的假新闻安全和道德问题,所以Sora不一定会很快正式发布,但因为transformer加diffusion已经成为了业内普遍尝试的方向,这个时候,OpenAI需要展示出Sora的能力,来在目前竞争日益白热化的生成式AI视频领域中重声自己行业的领先地位。
而有了OpenAI的验证之后,我们基本可以确定的是,AI视频生成方向会转变到这个新的技术结合。而OpenAI在发表的技术文章中也明确指出,在ChatGPT上的巨量参数“大力出奇迹”的方式,被证明在AI视频生成上。

OpenAI在文章中说,“我们发现,视频模型在大规模训练时表现出许多有趣的涌现功能。这些功能使 Sora 能够模拟现实世界中人、动物和环境的某些方面。

这说明,Sora和GPT3的时候一样,出现了“涌现”emergence,而这意味着,与GPT大语言模型一样,AI视频也需要更多的参数,更多的GPU算力,更多的资金投入。
Scaling,依然是目前生成式AI的绝招,而这可能也意味着,生成式AI视频也许最终也会成为大公司的游戏。
张宋扬博士,Meta Make-A-Video模型的论文作者之一、亚马逊AGI团队应用科学家:
我觉得可能更直观的就是相当于你,比如说你一个视频可能存下来是几十个GB,然后可能到大语言模型就得大一千倍了,就得上TB了,就是大概是这么个意思,但是我觉得应该是能看到这样一个趋势的,就是就虽然现在视频的参数量只是在billion级。
但是像图片里面他们之前stable diffusion模型,他们后来出了一个stable diffusion XL,他们也是把模型做大了,然后也带来了一些比较好的一个效果,也不是说比较好的效果,就是他们能做更真实的那图片,然后效果也会更明显一些。我觉得这是一个趋势,就是未来肯定会把参数量做大的,但是说它带来的增益会有多少,也取决于你目前的这个模型的结构以及你的数据量,你的数据是什么样的。
以上是我们对Sora非常初步的分析,再次说明一下,因为Sora非常多技术细节没有公开,所以我们的很多分析也是从外部视角去做的一个猜测,如果有不准确的地方,欢迎大家来纠错,指正和探讨。
作者:陈茜inTheValley
来源公众号:硅谷101(ID:TheValley101)
]]>
最近,Sora的公布给所有行业的人带来了狠狠地Impact,所有从业者都在期待着AI动画/视频技术的革新,并为行业带来的效率提升。
本文将从游戏行业从业者的视角出发,谈谈当前对于AI动画/视频的一些思考。BTW,目前AI技术日新月异,本人对于某个领域的能力的AI技术认知可能有所滞后,欢迎指正。
一、游戏行业的美术资源
游戏行业是一个严重依赖美术资源的行业。无论是在游戏的研发、营销还是运营过程中,都需要大量的美术资源。
1. 研发侧
在游戏研发阶段,策划设计游戏玩法和系统,将其交由美术团队进行角色、界面和场景设计,最终由开发团队完成游戏的开发和测试工作。根据游戏类型的不同,所需的美术资源也会有所差异。
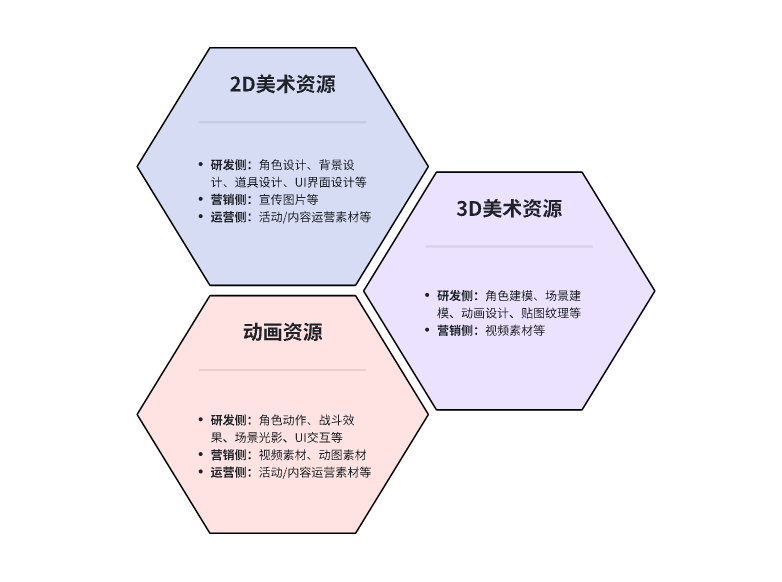
美术资源主要分为:
- 2D美术资源(如角色设计、背景设计、道具设计、UI界面设计)
- 3D美术资源(如角色建模、场景建模、动画设计、贴图纹理)
- 动画资源(括角色动作、战斗效果、场景光影以及UI交互等)
根据东方财富证券的报告,游戏研发成本占收入比约在 15%-35%,美术成本一般占到游戏研发成本的 50-70%。根据伽马数据,2023年中国游戏市场实际销售收入3029.64亿元。因此,此处美术成本约为200~800亿元。
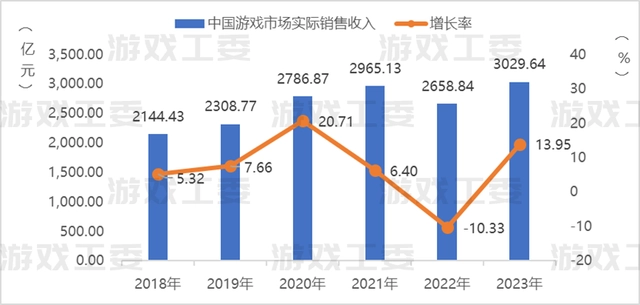
数据来源:游戏工委、伽马数据(CNG)
2. 营销侧
在游戏开发完成后,游戏公司需要进行游戏营销,以有限的成本吸引更多精准的用户。常见的获客手段包括投放广告、联合运营和品牌宣传等。在营销过程中,需要大量的营销美术资源,如图片、动图和视频,用于广告投放、联运商城以及品牌宣传。比如,我们常见的洗脑广告视频,这些是由真人拍摄的广告视频。

根据游戏新知的数据,营销一直是游戏公司支出的重要部分,因此对美术资源的需求也非常高。
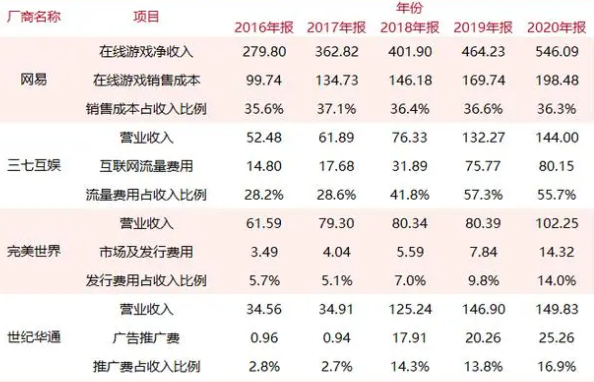
3. 运营侧
一旦吸引用户进入游戏,运营团队的主要任务是促进用户活跃、提高留存率并引导用户进行付费转化。在运营过程中,需要大量的美术资源,与营销所需的素材相似,但主要用于运营活动和社群内容构建,包括图片、动图和视频等美术素材。
综上所述,游戏行业对美术资源的需求主要分为3类:2D美术资源、3D美术资源和动画资源。
二、当前游戏行业美术对AI的应用
根据伽马数据的报告显示,自AI绘画技术问世以来,某游戏企业在美术方面取得了显著进展。据称,该企业目前在美术方面的成本节省率达到40%,文案创作效率提升超过50%,而未来在研发端,整体成本预计将下降30%。以往需要两周完成的2D美术资源生产,如今仅需3天便可完成。
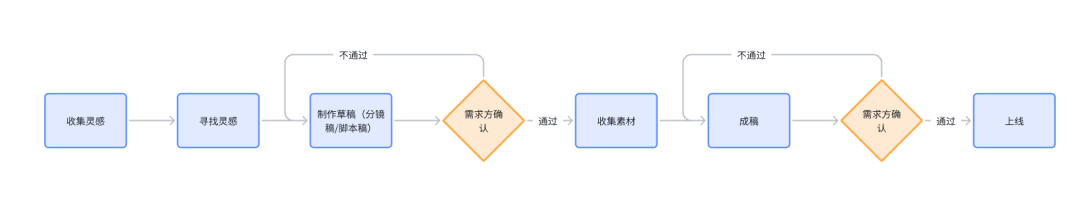
一个完整的2D美术资源的生产应该包含以下流程:

然而,由于当前AI技术的“可控性”和“稳定性”仍有提升空间,因此AI工具主要在激发灵感、制作草稿以及需求确认等方面发挥作用。
尽管部分素材可以直接采用AI生成的成稿,但这仅适用于少数情况。美术人员可以通过文生图/图生图等方式进行抽卡,激发创作灵感,并快速形成草稿,从而显著提高美术资源的生产效率。
同时,借助已生成的草稿,可以快速与需求方进行对齐。或者,需求方可以通过AI工具生成样图,与美术人员进行需求确认。这种方式可以大大减少由沟通问题导致的需求差异,从而减少返工情况,进一步提高美术资源的生产效率。
当前,虽然在3D美术资源领域已经出现了一些能够快速生成资源的工具,但相比之下,仍未有2D美术资源的生成成熟,然而这方面的讨论将暂且搁置。在美术资源的各个类型中,AI视频工具在动画美术资源的制作中发挥着一定的辅助作用,尽管也存在一些挑战。根据前文的分析,游戏行业中动画素材的制作场景主要涉及以下方面:
- 研发侧:角色动作、战斗效果、场景光影、UI交互等;
- 营销侧:视频素材、动图素材;
- 运营侧:活动/内容运营素材等;
所有这些方面都可以通过与AI动画/视频相关工具的结合来实现成本降低、效率提升的目标。
我们先拆解下现在动画素材制作的流程,主要有以下环节:
1. 寻找灵感
在进行动画素材的制作之前,美术人员通常会利用第三方平台进行调研,以收集灵感和素材。
对于营销层面的视频素材的制作灵感收集,他们使用像DataEye、AppGrowing等网站,这些平台汇集了广告领域中最热门和最新的视频素材。通过这些调研,制作者可以了解哪些素材在广告投放中效果良好、哪些是当前热门的素材,以及哪些具有潜力,从而指导他们的视频素材创作。
然而,海量数据分析是一项耗时耗力的工作。动画/视频制作本身就是一个人力密集型的过程,如果还需要额外的时间用于灵感收集,那将增加额外的成本。
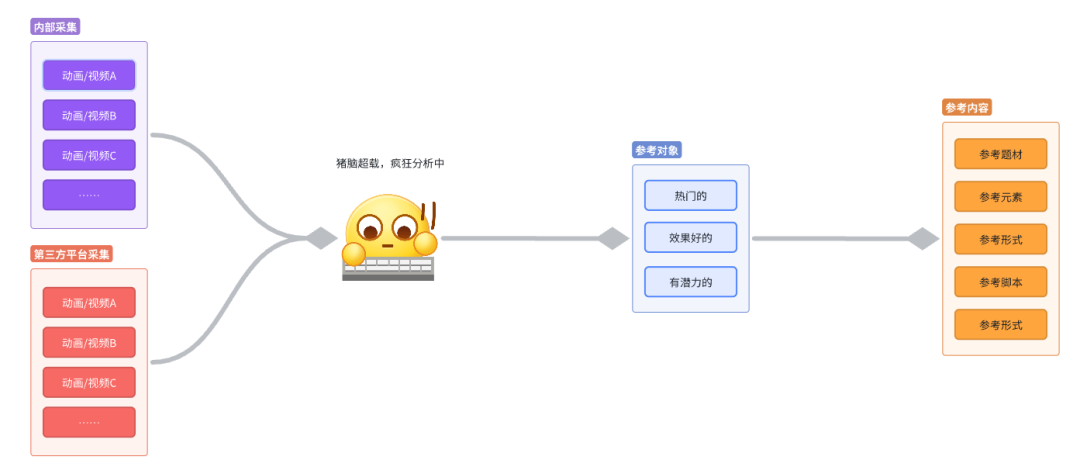
热门且效果良好的素材具有明显的数据特征,可以通过数据规则快速提取,但仍需要人工识别其中的参考内容。而那些具有潜力的素材则往往没有明显的数据特征,因此只能在海量数据中进行挖掘,有些许像大海捞针。
假设我们能够应用AI技术来增强业务能力,通过AI动画/视频分析,系统可以解构视频中的元素并进行标签分类,将这些分类信息存储在灵感库中,以便设计师快速提取灵感,同时也有助于快速发现潜力内容。通过AI技术,我们可以将海量数据浓缩为高价值信息,从而提升业务生产效率。
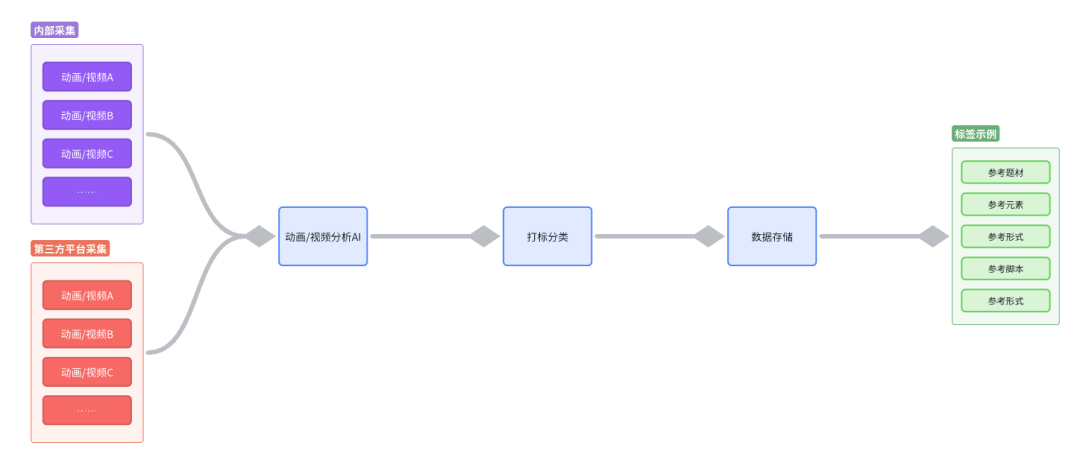
目前,B站提供了AI视频分析功能,但仅适用于部分视频。没有配音或字幕的视频以及发布时间早于24年的视频无法使用该功能。估计B站的AI视频能力主要通过OCR和语音识别技术提取视频文本内容,并将其提交给LLM进行总结。
然而,游戏的动画/视频素材生产,更多的是涉及没有文本内容的画面(角色动作、战斗效果、场景光影、UI交互、游戏实况视频等)。类似于B站的视频分析能力,目前还无法从这些画面中提取信息。这就需要依赖基于视觉内容的AI分析模型。目前一些SaaS厂商提供了相关能力,但是要提炼出美术设计师所关心的内容仍然具有一定难度,因此这些模型更多地用于视频内容审核。
图片来源于商汤(左)和网易易盾(右)
2. 制作草稿
动画素材实质上是2D/3D美术资源在时间维度上的延续,因此动画的草稿相对复杂,涉及脚本、分镜等设计内容,其中的沟通成本和试错成本远高于2D/3D美术资源。
目前存在几个方向的AI视频/动画工具,可以在制作草稿过程中发挥作用:
1)素材搜索匹配:
在调研过程中,发现一类AI动画/视频工具,通过输入文本/图片,AI能够匹配相关度较高的视频素材并进行拼接,同时使用AI声音进行配音,快速生成相关动画/视频内容。
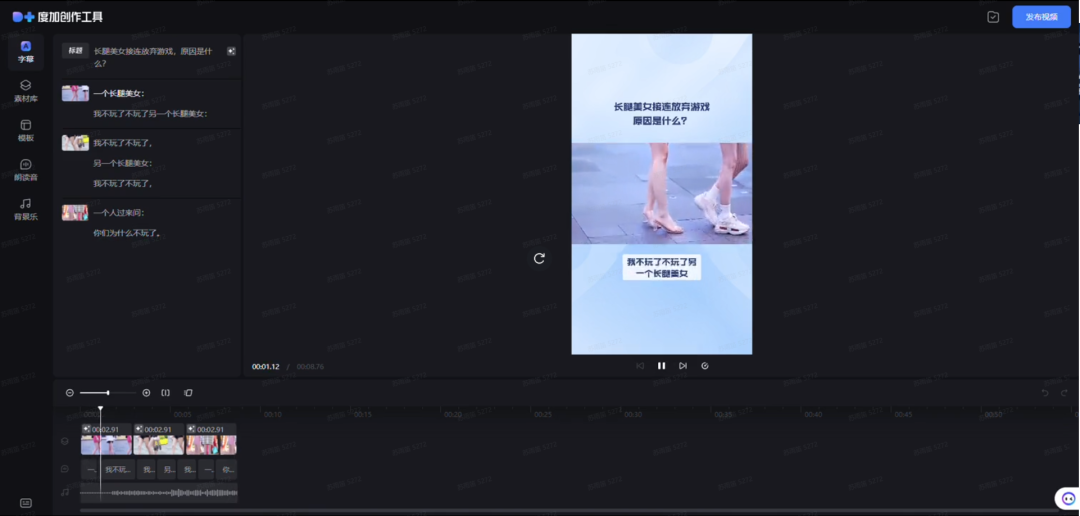
图中为度加创作工具
这类AI动画/视频工具的核心在于素材搜索匹配能力。
通过对素材库中的视频进行分析、拆解、打标签,再根据用户的提示词匹配最合适的动画/视频内容,从而拼接成动画/视频。这个过程涉及到AI文本生成、语音合成、动画/视频剪辑等能力,可以归类为剪辑工具。
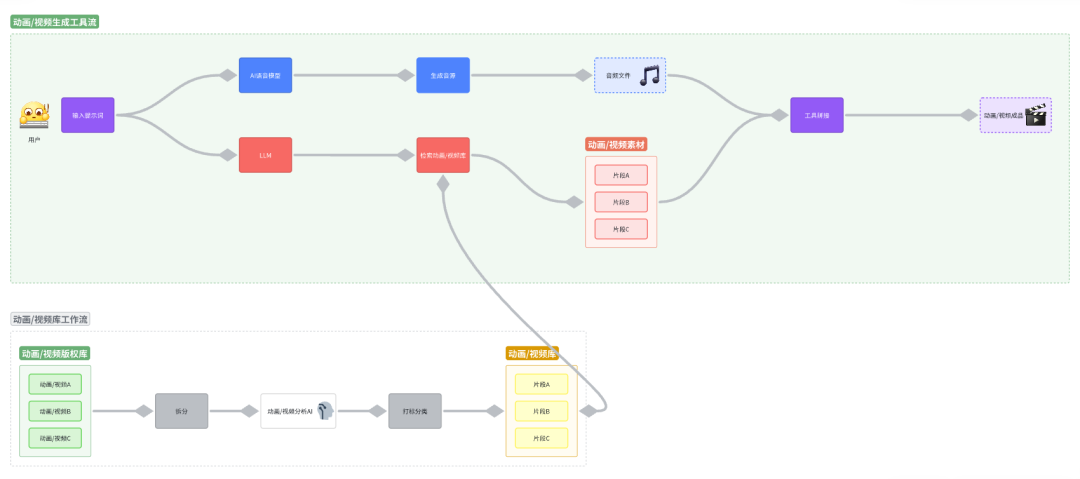
然而,当前这类工具可能存在以下问题:
i)素材上下文相关性:
由于视频是由多个素材拼接而成,若AI无法理解素材之间的关系,在动画/视频剪辑过程中使用了矛盾的素材,将影响最终成片效果。
ii)素材版权:
生成的动画/视频片段来源于其他视频素材,可能涉及版权问题。工具需要解决和规避侵权内容的识别问题。
iii)素材库的大小:
素材库规模的大小直接影响这类视频生成工具的效果和生成的视频多样性。庞大的素材库需要大量版权资源或内容平台支持,从而构建工具的“网络效应”,而较小的素材库会限制工具的效果。
因而,这个方向的AI工具,内容巨头企业才更容易做得更好。
iv)搜索匹配的准确度:
动画/视频分析AI对动画/视频内容的理解有限,导致搜索匹配结果准确度问题,与用户设想的画面可能存在一定差距。在生成多个动画/视频片段拼接而成的视频时,准确率问题会叠加,使成品动画/视频偏离原始设想。
这些问题导致素材搜索匹配相关的AI产品工具,在当前并不是那么好用。
2)文/图生视频:
Sora属于文/图生视频的AI方向。在Sora发布之前,市场上已有相关工具如Pika、RunwayGen2、Stable Video Diffusion,它们可以根据用户输入的文本或静态图片,生成几秒钟的视频/动画。
然而,目前市面上的文/图生视频AI工具存在明显缺陷,例如:
i)未能理解物理世界:
正如Runway之前宣布要通用世界模型(General World Model),像Gen-2这样的视频生成AI,仅仅是生成了具有有一定运动的短视频,但是在处理摄像机运动或物体运动等问题上存在局限。
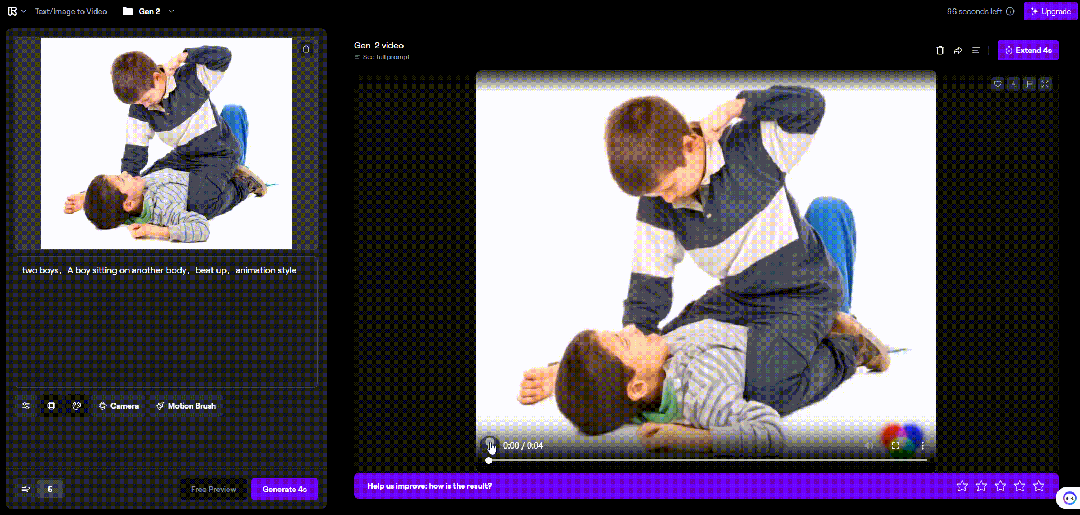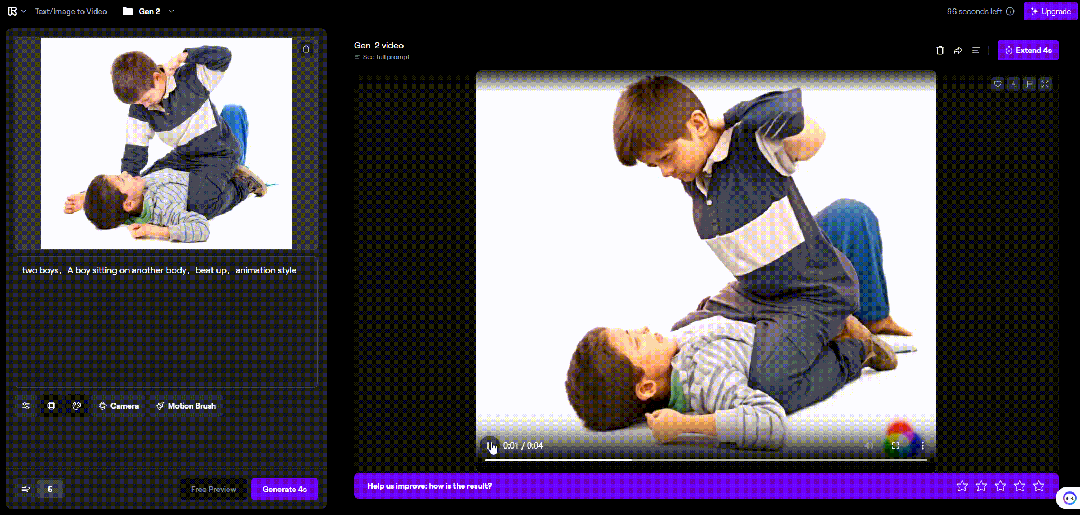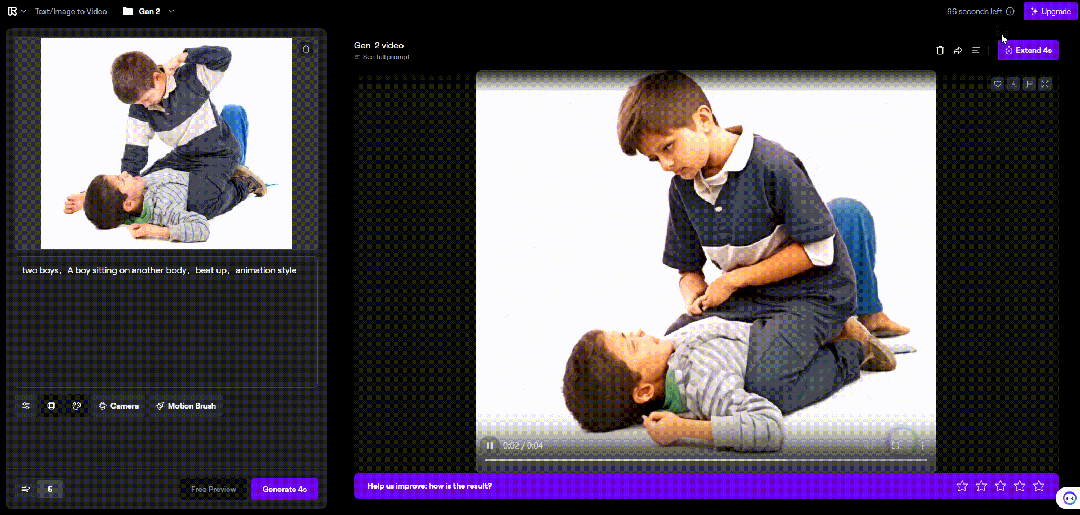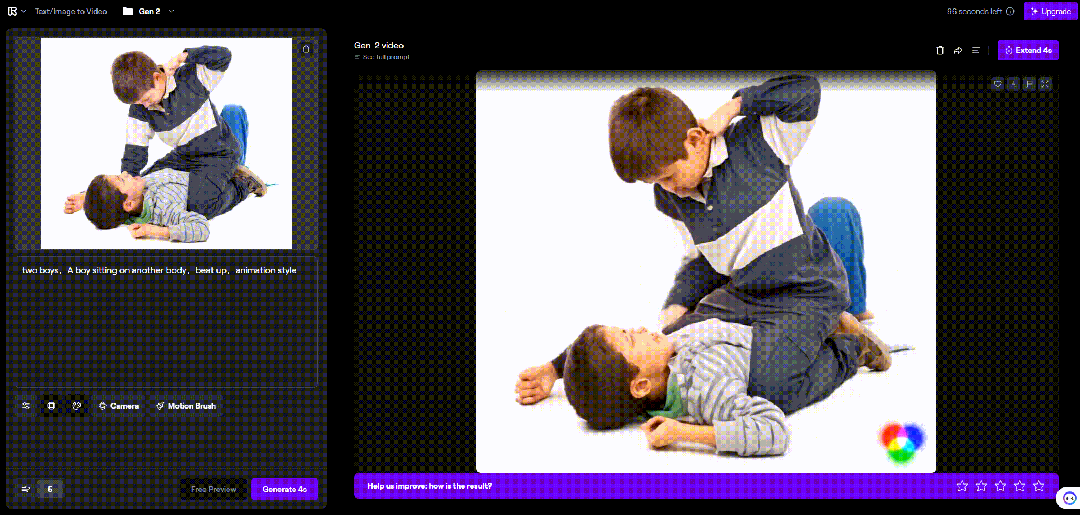
比如这里,我用张俩男孩打架的图片,生成的视频中,男孩挥出去的手反而贯穿了自己的脑袋。
虽然Sora也具备了通用世界模型的基础能力,但是也同样存在“对物理世界理解不足”的问题,比如知名的“玻璃破碎”、“虚空椅子”。这些训练数据不足的情况,使得在多主体之间的运动无法被准确表达。

ii)主体一致性问题:
在AI生成的动画/视频中,人物外貌、动作等可能随着人物动作的变化而发生变化,导致主体一致性问题,影响视频质量。如下图的案例中,原本是生成马斯克的视频,但是在视频的最后几秒,马斯克变成了一个黄种女人。

视频素材来源于知乎用户sunny
iii)无法生成游戏行业垂直内容:
像是角色动作、战斗效果、场景光影、UI交互、游戏实况视频等内容,AI工具的生成效果极差。因此对于游戏行业,大概率仅有视频类动画素材的生产过程才能用上这类AI工具。
3. 收集素材
制作视频类动画素材涉及收集素材的过程,其中需要结合分镜稿,收集足够的素材以供剪辑使用。这一过程与制作草稿的工具需求大致相同,可以借助“素材搜索匹配”和“文/图生视频工具”的AI能力来辅助。
4. 成稿
一旦素材齐全,下一步就是将所收集/制作的素材拼接成最终的成品稿。这个过程涉及到多种类型的AI动画/视频工具,种类繁多且多样,较难一一概括,以下是我观察到的一些类型,而且大多都只能用在视频类型的素材剪辑上。
1)视频拆条:
这类工具旨在快速将视频按需求进行剪辑拆分和拼接。举例来说,火山引擎提供了“视频拆条”功能,利用AI画面和语音识别自动将视频进行拆分,同时支持对视频进行进阶设置。这种工具可用于对长视频进行分割处理,以便进行短视频合成。

又比如,“vidyo.ai”提供的视频拆条能力,在基于语音识别的基础上,还提供了针对不同内容平台的格式转化能力。
2)配音:
语音配音在制作视频类内容时扮演着重要的角色。尽管在严格意义上,配音并不属于AI视频工具的范畴,但却是制作视频内容不可或缺的一环。当前的AI生成语音技术已经相当成熟,以剪映官方为例,他们提供了完善的配音音色功能,用户可以通过输入文本生成对应的音频内容。
3)字幕:
视频制作中不可或缺的一环是字幕。随着技术的发展,字幕生成技术也日趋成熟,例如,剪映已经具备了自动生成字幕的能力。
4)画面编辑:
我觉得很多视频工具都可以归到这一类里面,比如视频剪辑软件里面都会配备的滤镜能力,通过应用特定的滤镜效果,使视频呈现出特定风格和视觉效果。
同时,市面上也有能将够稳定将视频转换成其他风格的工具,如Ebsynth。

Runway里面除了视频生成能力,还提供了像是一键删除背景、一键修复、一键模糊等效果编辑AI。
perfectly-clear提供的编辑能力可用于改善视频的色彩、提高对比度、消除噪点、改善视频的清晰度,以及消除视频中的抖动和模糊。

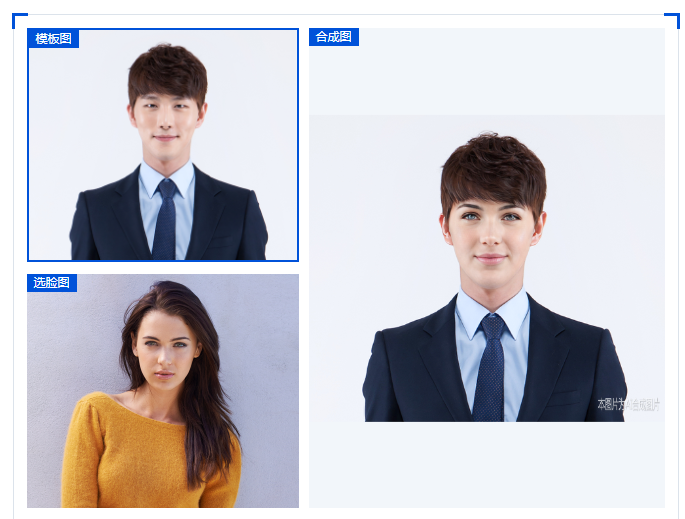
腾讯云提供的AI换脸技术将真人视频中的人脸替换成其他人脸。
5)数字人:
几乎所有主要厂商都在积极探索并应用这一技术。其核心在于利用AI生成个性化的数字人物,并结合专属的AI音色,使得这些AI数字人可以替代用户进行视频解说。在直播带货等场景中,这种技术不仅可以提高效率,还能有效节省人力成本。

四、小结
结合我的调研,目前游戏行业相关的AI视频/动画工具可分为4大类:
- 动画/视频分析:利用人工智能的分析和理解能力,提炼出美术设计所关注的核心信息,将大量信息压缩成关键要点,从而提高寻找灵感的效率。
- 素材搜索匹配:基于视频分析的AI技术,通过对素材库中的视频进行分析、解构和标记,再根据用户提供的关键词匹配最适合的动画/视频内容,提高视频类动画资源制作的效率。
- 动画/视频生成:基于生成式AI技术,能够通过文本和图像内容生成动画视频内容。
- 剪辑工具类:辅助动画资源的制作,提高制作效率。
目前的AI视频/动画工具更多偏向于视频类动画素材的生产,更适用于与营销相关的业务生产,因为这方面对于大型模型的定制化要求较低。然而,对于与动效相关的动画生产,可能需要游戏行业垂直领域大型模型能力的进一步发展。
我将收集到的AI视频/动画工具给到美术设计,他们的回答是:“好像什么都能做,但是又好像做不好的感觉。总不能为了这碗醋(使用AI),才包的这顿饺子吧(做动画/视频)。”剖析其中的原因,主要是:
- 素材搜索匹配、视频生成类当前AI工具对于游戏行业垂直程度不够高,无法生成足够高准度的内容。而且动画素材有别于图片素材,AI图片生成内容的准确度不高时候,美术还可以上手修改,但是当AI视频生成的准确度不高的时候,逐帧修改成本过高,不具有可行性。
- 工具分散,未能较好贴合生产流程。大部分的AI工具分布在不同的平台上,“收集灵感”——“制作草稿”——“收集素材”——“剪辑成稿”的过程需要跳转的平台过多,同时各类工具的更新和版本调整也需要人力去跟进和维护,再加上大部分工具使用场景很小,单独购买性价比不高。整体需要耗费过多的精力和成本,这有碍于AI工具对于制作的提效。
- 由于工具使用都是分散在各类工具平台上,AI工具的使用不能进行AI资产的积累,无法形成工具使用的“边际成本递减”。(比如文/图生图的AI使用,可以通过低模型训练、参数调试的方式,快速将AI工具变成业务的形状,提高生产效率)
- 目前收集到的大部分AI视频/动画工具,普遍都是需要收费的。要么按请求量收费,要么是会员制,动则每个月上百块。结合前文提到的AI准确度不高和工具分散问题,业务可能需要在多个平台多次“抽卡”(调侃准确度不高,就好像游戏抽卡那样,需要N次才能出来想要的结果),这个过程大大加大了成本的消耗,使得AI的使用成本甚至可能高于人肉。
随着越来越多AI公司的入局,以上提到的问题一定会被解决,正如万物摩尔定律所描述,成本问题也会越来越低。Sora的出现,无疑是对这个过程的加速。
但是我也想谈谈我对未来展望的一些观点,我觉得未来的AI动画/视频工具一定是背靠视频剪辑/动画制作工具的,并集成大多数的AI工具(All in one),因为:
1.工具集成&贴合工作流带来的用户体验优势:
视频剪辑/动画制作工具本身就是贴合用户工作流程的产品形态。当AI工具集成在一起时,用户可以直接利用AI能力进行生产,无需研究各种AI工具,减少额外精力消耗。同时,基于用户使用习惯,产品可以提供AI数据资产积累能力,定制化模型,更贴合用户使用习惯,构成用户的沉没成本。
2.用户增长优势:
现有视频剪辑/动画制作工具已有一批忠实用户群体,发展AI能力时无需从零开始用户增长。在成熟工具上构建AI能力,加固了产品壁垒。
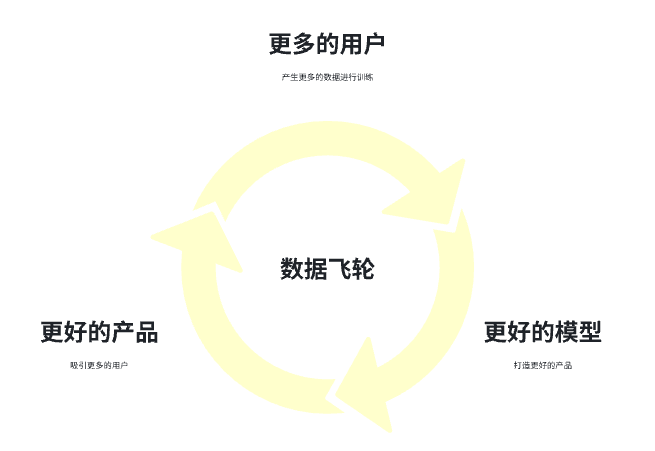
3.更容易构建数据飞轮,构建数据壁垒:
借助平台原有的用户积累,能够利用庞大的素材积累、数据积累训练优秀的大模型,打造优质的视频产品功能,从而吸引更多用户,构建数据飞轮,构建自身的壁垒。
4.工具更具有可控性问题的解决方案:
AI动画/视频生成工具是具有本质上的矛盾的,文本是低维信息,却需要准确表达动画/视频这种高维信息,这个过程必定伴随信息的失真。文生视频必定是不能100%传达制作者的想法的。这个过程就需要编辑工具的存在,通过人工编辑的接入,将内容准确表达。而且,通过编辑工具,我们也能通过人力弥补AI的准确度问题,使得在AI能力能准确生成我们需要的内容之前,我们也能利用AI进行效率的提升。
因此背靠视频剪辑/动画制作工具,更容易进行编辑工具构建,从而解决可控性问题。
作者:柠檬饼干净又卫生
来源公众号:柠檬饼干净又卫生

在暖色灯光中,一个复古行李箱缓缓打开,露出灰白色的运动鞋,光影在鞋面上划过,镜头拉近,麂皮质地的纹理清晰可见。画面一转,鞋子旋转起来,灯光由暗转亮,明暗交接在鞋跟处形成一个慢镜头的色彩对比,一边明亮、一边典雅。
这个20s的商品展示视频,角度丰富、色彩讲究、镜头多变,但并非来自摄影机实拍,而是由AI通过几张照片生成。
短视频在电商营销领域的重要性毋容置疑,而AI将代替人工将短视频生产效率大幅提高,“AIGC让我们一天能生产10万条短视频。”时代涌现联合创始人茅旭超在亿邦峰会上表示。
这就是大模型带来的新型生产力。
从技术发展角度看,AI视频生成经历了图像拼接生成、GAN/VAE生成、自回归和扩散模型三个发展阶段,目前已经应用于影视预告片、广告、虚拟场景/角色/特效、老电影/珍贵影像资料修复等领域。
随着短视频工业化能力的大幅提升,广告营销公司、MCN机构、影视公司、游戏公司都在迎来新变革。
一、短视频自动生成,成本1/10
“国内对短视频的需求强烈,主要来自电商平台的流量扶持。”极睿科技CEO武彬分析。
极睿科技从事电商营销6年,通过AI自动生成海量商品营销内容。武彬注意到,短视频需求的爆发,始于2022年淘宝、京东、唯品会等电商平台的全面视频化。比如作为淘系流量新入口的淘宝逛逛,2021年上线,2022年淘宝逛逛被列为和淘宝直播平级的部门。
有官方扶持意味着大流量和高投入产出比,商家只需要通过制作和发布视频就可以实现流量增长。“因为平台有流量扶持,所以品牌的每一个SKU都有了被视频化的必要。”武彬指出。
只不过在2022年,短视频的制作能力尚且跟不上各个平台爆发的短视频需求。
传统的人工生产视频成本100-500元/条,拍一套服装展示的短视频需要先找模特、找场景,然后美工P图、裁图、做主图、做详情页,第三步剪辑短视频,第四步运营,做商品上下架管理,第五步多平台种草,在淘宝、京东、抖音、小红书等平台发布,第六步根据种草情况进行调整。

图片来源:极睿科技
与手工作坊相比,大模型带来了工业化的视频生产方式。比如,时代涌现提供的超麦视频,可以将品牌的所有产品图全部视频化,“我们可以根据同一个详情页,生成无数视频。因为每一次AI调用的镜头和生成视频是不一样的,在这样的服务框架下,我们可以帮品牌生成无限量的基础视频,在公域中获得流量。”茅旭超介绍。
大模型将短视频的制作成本降低至原本的1/5-1/10。“之前我一年要做1万条视频,成本100多万,现在可能20万搞定。而且这个需求没有边界,这个行业里的这些商家都需要,只是以前做不到而已。”武彬指出。
大模型这一新的生产力,也在改变着品牌的内容营销方法和广告公司、MCN机构的生存方式。
茅旭超注意到,过去品牌的内容营销是倒三角形:
- 针对1%-5%的爆品,内容高预算高质量,广告公司或者4A创意机构制作;
- 针对10%-15%的核心款,内容低预算高质量,影棚或制作公司生产;
- 针对70%-80%的长尾款,内容低预算低质量,电商代运营或内部职能部门制作。
现在有了AIGC,品牌可以针对不同级别的产品,制作不同的AI内容:
- 针对1%-5%的爆品,AI创意脚本+高精度3D模型,合成高质量3D创意视频。
- 针对10%-15%的核心款,提供AI智能混剪、AI虚拟人测评/讲解视频、AI商品(3D)表达视频。
- 针对70%-80%的长尾款,通过AI快速让品牌的所有产品图动起来——AI商品2D表达视频、AI淘宝详情页头图视频、AI淘宝微详情视频、AI旁白混剪视频、AI模特换装效果图等。
国内还流行基于语义识别和视觉识别,智能抓取直播讲解片段并混剪分发的直播切片。比如极睿科技推出的iCut,自动识别直播过程中的卖点片段,无需剪辑就可以一边直播一边实时获得海量短视频素材,帮助直播卖家通过短视频引流获客和持续成交。

图片来源:极睿科技
时代涌现则通过自研大模型FancyGPT,自动生成商品视频——只要输入一个商品的链接地址,FancyGPT会自动解析生成代码,在时代涌现的视频渲染软件中自动完成视频制作。“只要品牌把商品店铺ID给到我们,我们可以自动解析品牌电商店铺里面所有素材的信息、图片、视频、文本描述。通过全自动方式调用素材,重新做整合,自动生成视频。”茅旭超介绍。
短视频引流效果十分惊人。某知名羽绒服抖音直播间超90%的流量来自直播切片和图文视频的引流。“在我们合作的一些店铺中,短视频带来的流量一度占到了全店流量的98%。品牌其他地方的流量没有下降,这就是平台对于短视频的扶持,导致短视频流量增长非常快。”武彬指出。
2023年,极睿科技有望实现四倍增长。4月极睿科技的iCut demo版上线,受到客户的欢迎,“那个时候智能化程度还没那么高,还需要一些人工来配合,但引流效果确实不错。之后就客户就开始大量采买视频,真正起量在七八月份。”武彬记得。
时代涌现的营收也预计翻三到四倍,他们还将业务从线上营销扩展到线下门店,将门店海报替换为大屏幕,在线下展示优质短视频内容。
二、大模型文生视频,群雄竞起
不久前,有人将大热的《奥本海默》和《芭比》合在一起做成一部预告片,用ChatGPT写脚本,Midjourney生成图像,Runway Gen-2生成视频,粉色的摩登女郎和铁灰色的工程机械融合得巧妙,情节新颖,画面真实。

图片来源:Twitter
自从2023年4月Runway上线新产品GEN-2,可以用文字、图像或视频片段生成新视频,视频创作的玩法就五花八门。
一段话可以生成一个短视频。

图片来源:Twitter
一张图也可以生成一个短视频。

图片来源:Twitter
在本轮AI浪潮中,文生文、文生图、文生视频/图生视频一直并行发展,ChatGPT代表了文字生成的率先突破,Midjourney将文生图推到人人可用,视频是多帧图像的组合,文生视频在文生图的基础上增加了时间维度,需要更多算力资源、理解能力和生成能力。
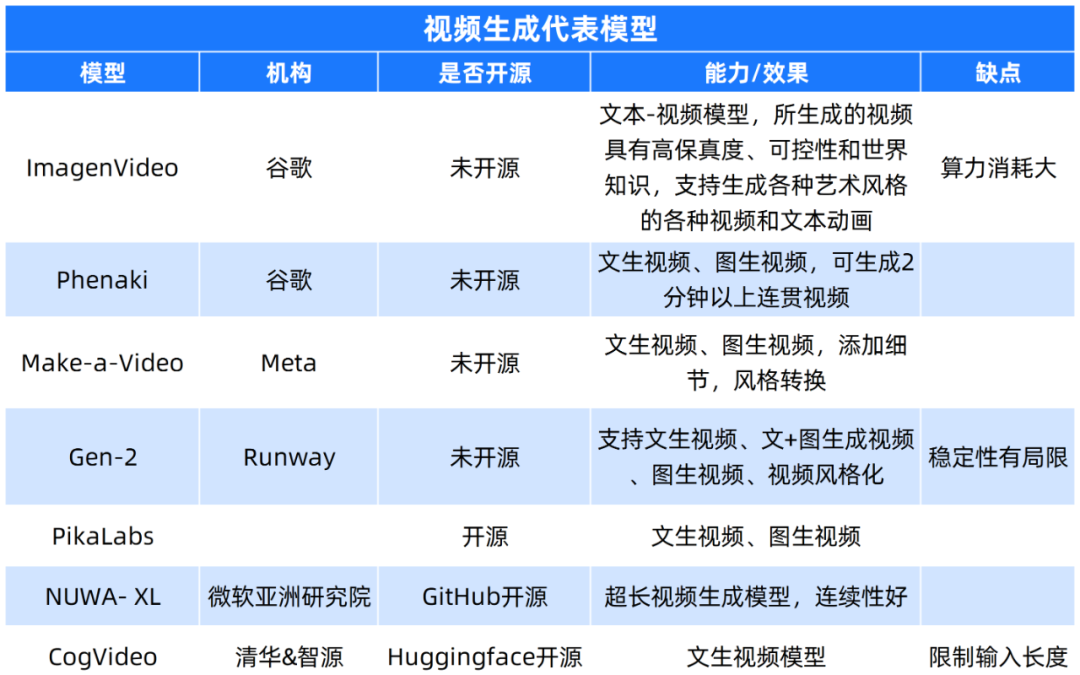
目前文生视频底层技术仍在优化,最优模型尚未出现,文生视频仍在探索如何实现高分辨率视频生成、超长文本的视频生成和无限时长的连贯视频生成。
谷歌在视频质量和视频长度上分别发力,推出Imagen-Video和Phenaki两款产品抢占市场;Meta发布Make-a-Video视频生成模型,让细节更逼真;OpenAI发布的GPT-4更是增加了多模态能力,打通文字、图片、视频、3D之间的转换能力;微软在GitHub上开源NUWA系列,发布NUWA- XL超长视频生成模型。
阿里达摩院上线的文生视频模型“Zeroscope”,试图与GEN-2正面竞争,阿里云还发布了一个数字人视频生成工具Live Portait,可以通过上传一张照片和一段文本,生成一段开口说话的数字人视频;文心一言通过视频插件Text2Video,实现文心一言编写脚本,插件生成视频;腾讯智影也让数字人可以开口说话。
AI视频生成在影视行业中已经得到应用。Runway参与了《瞬息全宇宙》的特效制作,仅靠五人就完成了电影后期制作,名场面 “热狗手”还获得好评。
《流浪地球》导演郭帆也公开表示,“《流浪地球》第三季如果拍摄的话,现场可能至少一半以上的人会减少掉。人工智能对我们来说既是挑战,也是机遇,可能是我们弯道超车好莱坞的机会。”
三、营销技术变革,谁先吃到红利
影视行业对时长、动作连贯性和画面逼真度要求更高,而视频营销对分辨率和连贯性的要求较低,更重视制作成本与引流效果。
同时,大模型应用层的创新也有窗口期,短视频营销正在直面大厂竞争。2023年上半年,大厂相继在研发各自的通用模型,应用层厂商率先利用AIGC取得抢跑优势。下半年,大厂大模型整装待发,大厂相继推出适用于各自平台的AIGC营销产品,比如阿里妈妈的“万相实验室”,京东的“云鼎权益”。
时代涌现创始人 William Li(花名:空界)曾是天猫奢品Luxury Pavilion初代负责人,时代涌现从成立之初便瞄准聚焦营销领域,只做基础物料生产。
据了解,时代涌现在技术上推出自研大模型FancyGPT——基于LLaMA模型调参600亿的大模型,可自动完成营销视频制作;在运营上实现多平台内容的管理和生产,可以把各平台的直播素材混剪成视频,一键投放至线下大屏。“我们更多解决的不只是一个平台,而是整个品牌的资产性问题。”时代涌现CRO默羽强调。
除了电商营销,时代涌现还注意到4A公司和线下营销的生意。“电商营销50亿规模,广告150亿规模,线下营销150亿规模,这350亿规模的市场,足够我们深耕。”默羽介绍。
据武彬介绍,极睿科技成立了一家MCN机构,从团队抽调几个人做兼职,在淘宝精选联盟选择高佣金的商品连接,通过自研工具生成短视频并在淘宝平台分发。上线第一天成交100多万元,此后每天稳定在数十万至100万左右。8月10号注册到8月底,该MCN公司累计成交额已经达到900多万元。
当下的视频模型还处于发展初期,技术短板仍然不少,比如计算成本高昂——一个短视频每秒包含大约30帧图像,单个视频片段有数百数千帧,为确保每一帧之间空间和时间的一致性,需要大量的计算资源。
再比如,复杂信息难以处理——视频带有视觉动态信息,添加不同帧之间的时间信息后,对视频内容进行建模变得非常具有挑战性。
杰克韦尔奇曾提出过一个“10倍理论”:当新技术产生的效果能够10倍于原有技术,或者将成本降低至原有的1/10,新技术就能打穿旧有体系。
AI视频生成在内容营销领域已经将成本降低至1/10,同时将生产效率提升10倍。新技术的穿透力正在改变营销公司、广告公司、MCN机构的生存方式,这种改变还在继续。
作者:胡镤心;编辑:张睿
来源公众号:亿邦动力(ID:iebrun)